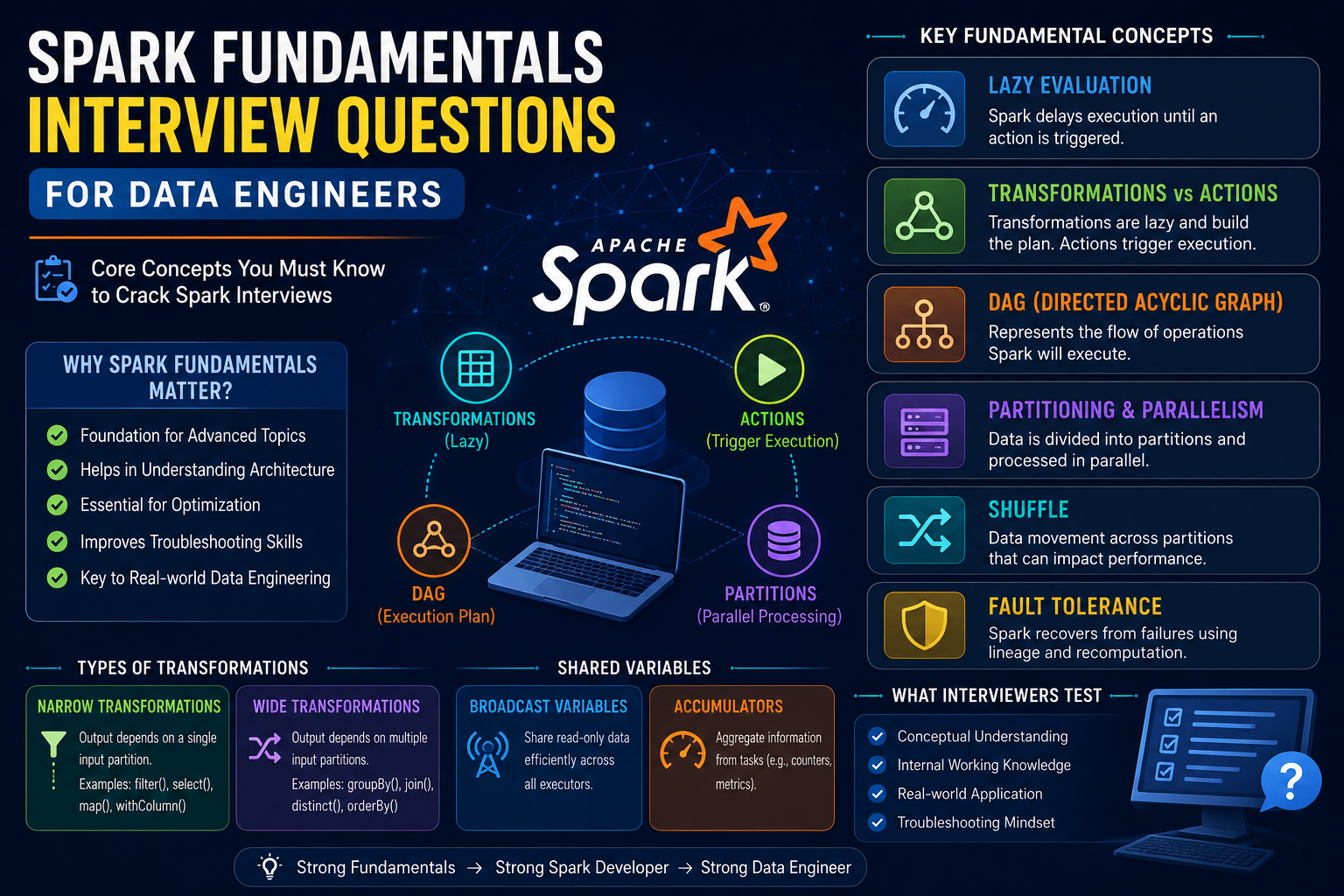
Spark Window Functions Interview Questions
Window Functions are one of the most powerful features in Spark and are heavily used in modern Data Engineering pipelines.
They allow you to perform calculations across a group of related rows without reducing the number of records, making them ideal for ranking, deduplication, running totals, moving averages, and time-series analysis.
In interviews, candidates are often asked questions such as:
- What is a Window Function?
- Difference between
ROW_NUMBER()andRANK()? - Difference between
LAG()andLEAD()? - How do Window Functions differ from
groupBy()? - How do you optimize Window Functions in Spark?
This guide is designed as a quick interview revision resource.
Instead of lengthy explanations, you'll find:
- Topic-wise interview questions
- Important concepts to revise
- Production scenario questions
- Rapid-fire revision
- Interview preparation tips
Let's get started.
Window Function Fundamentals Interview Questions
Questions
- What is a Window Function in Spark?
- Why are Window Functions used?
- Difference between Window Functions and
groupBy()? - How do Window Functions work internally?
- What is a Window Specification?
- What is
partitionBy()? - What is
orderBy()in Window Functions? - Why is ordering important in Window Functions?
- Can Window Functions be used without
partitionBy()? - Can Window Functions be used without
orderBy()? - What are the common use cases of Window Functions?
- Why are Window Functions widely used in ETL pipelines?
Key Topics to Revise
- Window Specification
- partitionBy()
- orderBy()
- Analytical Processing
- Spark SQL
Ranking Function Interview Questions
Questions
- What is
ROW_NUMBER()? - What is
RANK()? - What is
DENSE_RANK()? - Difference between
ROW_NUMBER()andRANK()? - Difference between
RANK()andDENSE_RANK()? - When should
ROW_NUMBER()be used? - Which ranking function is best for deduplication?
- How do ranking functions handle duplicate values?
- Can ranking functions be used without sorting?
- How do you identify the latest record using
ROW_NUMBER()? - How do you find the Top-N records using ranking functions?
- Which ranking function is most commonly used in production?
Key Topics to Revise
- ROW_NUMBER
- RANK
- DENSE_RANK
- Deduplication
- Top-N Problems
Analytical Window Function Interview Questions
Questions
- What is
LAG()? - What is
LEAD()? - Difference between
LAG()andLEAD()? - What is
FIRST_VALUE()? - What is
LAST_VALUE()? - What is
NTH_VALUE()? - How do you compare current and previous records?
- How do you compare current and next records?
- What are common use cases of
LAG()? - What are common use cases of
LEAD()? - How do you detect changes between consecutive records?
- How do you identify missing values in sequential data?
Key Topics to Revise
- LAG
- LEAD
- FIRST_VALUE
- LAST_VALUE
- Sequential Analysis
Aggregate Window Function Interview Questions
Questions
- Can
SUM()be used as a Window Function? - Can
AVG()be used as a Window Function? - What is a Running Total?
- How do you calculate cumulative sums?
- How do you calculate moving averages?
- What is a Rolling Count?
- How do you calculate cumulative maximum?
- How do you calculate cumulative minimum?
- Difference between aggregate Window Functions and
groupBy()? - When should aggregate Window Functions be preferred over
groupBy()?
Key Topics to Revise
- Running Total
- Moving Average
- Cumulative Calculations
- Aggregate Functions
- Window Aggregation
Window Frame Specification Interview Questions
Questions
- What is a Window Frame?
- What is
ROWS BETWEEN? - What is
RANGE BETWEEN? - Difference between
ROWSandRANGE? - What is
UNBOUNDED PRECEDING? - What is
CURRENT ROW? - What is
UNBOUNDED FOLLOWING? - How do you define a custom Window Frame?
- Why are Window Frames important?
- When should
ROWS BETWEENbe preferred overRANGE BETWEEN?
Key Topics to Revise
- ROWS BETWEEN
- RANGE BETWEEN
- Window Frame
- Frame Boundaries
- Window Specification
Window Function Optimization Interview Questions
Questions
- Why can Window Functions become slow?
- How do Window Functions trigger Shuffle?
- How do you optimize Window Functions?
- How does partitioning improve Window Function performance?
- Why does sorting increase execution time?
- How do you reduce unnecessary Window operations?
- How do you identify Window Function bottlenecks in Spark UI?
- How does AQE optimize Window Function execution?
- How do file formats impact Window Function performance?
- What are the best practices for optimizing Window Functions?
Key Topics to Revise
- Shuffle
- Sorting
- AQE
- Partitioning
- Spark UI
Production Scenario Questions
These are some of the most commonly asked production-based Spark Window Function interview questions.
-
How would you remove duplicate customer records while keeping only the latest record?
-
How would you identify the latest order placed by every customer?
-
How would you calculate cumulative sales for every region?
-
How would you compare today's sales with yesterday's sales?
-
How would you identify salary changes for employees over time?
-
How would you calculate month-over-month revenue growth?
-
How would you identify the Top 3 highest-selling products in every category?
-
How would you assign rankings to students with duplicate marks?
-
How would you calculate a moving average for daily sales?
-
How would you identify gaps in sequential order IDs?
-
A Window Function query is running very slowly. How would you optimize it?
-
Window Functions are creating excessive Shuffle. What would you investigate first?
-
Your pipeline processes billions of records every day. How would you optimize Window Functions?
-
Explain a real-world ETL pipeline where Window Functions are essential.
-
Explain when you would choose a Window Function instead of
groupBy().
Spark Window Functions Rapid Fire Questions
Quickly revise these concepts before your interview.
- ROW_NUMBER vs RANK
- RANK vs DENSE_RANK
- LAG vs LEAD
- FIRST_VALUE vs LAST_VALUE
- SUM vs Running SUM
- AVG vs Moving Average
- Window Function vs groupBy
- partitionBy vs orderBy
- ROWS BETWEEN vs RANGE BETWEEN
- CURRENT ROW vs UNBOUNDED PRECEDING
- Running Total vs Cumulative Sum
- Sliding Window vs Fixed Window
- Window Aggregation vs Normal Aggregation
- Ranking Functions vs Aggregate Functions
- Deduplication using ROW_NUMBER
Quick Revision Cheat Sheet
| Topic | Remember |
|---|---|
| Window Function | Performs calculations without reducing rows |
| partitionBy | Creates logical partitions |
| orderBy | Defines row ordering |
| ROW_NUMBER | Unique sequential ranking |
| RANK | Ranking with gaps |
| DENSE_RANK | Ranking without gaps |
| LAG | Returns previous row value |
| LEAD | Returns next row value |
| FIRST_VALUE | First value within the window |
| LAST_VALUE | Last value within the window |
| Running Total | Cumulative calculation |
| Moving Average | Rolling calculation |
| ROWS BETWEEN | Physical row-based frame |
| RANGE BETWEEN | Value-based frame |
| Spark UI | Used to identify Window execution bottlenecks |
Interview Preparation Tips
Before attending Spark interviews, ensure you can confidently explain:
- How Window Functions differ from
groupBy(). - The differences between
ROW_NUMBER(),RANK(), andDENSE_RANK(). - When to use
LAG()andLEAD(). - How to calculate running totals and moving averages.
- The purpose of
partitionBy()andorderBy(). - The difference between
ROWS BETWEENandRANGE BETWEEN. - How Window Functions impact Spark execution and performance.
- How to optimize Window Functions on very large datasets.
- How to identify Window Function bottlenecks using Spark UI.
- Real-world ETL use cases involving Window Functions.
A good exercise is to solve common interview problems such as finding the latest record, removing duplicates, calculating cumulative sums, ranking records, and identifying previous or next values. These problems appear frequently in Data Engineering interviews and help build confidence with Spark Window Functions.
Common Mistakes Candidates Make
Many candidates understand the syntax of Window Functions but make mistakes in choosing the correct function for the problem.
Some common mistakes include:
- Using
RANK()instead ofROW_NUMBER()for deduplication. - Forgetting to specify
orderBy()while applying ranking functions. - Confusing
ROWS BETWEENwithRANGE BETWEEN. - Using Window Functions when a simple
groupBy()is sufficient. - Applying multiple Window Functions separately instead of combining them efficiently.
- Ignoring the performance impact of sorting and Shuffle.
- Not partitioning data appropriately before applying Window Functions.
- Assuming all Window Functions have the same execution cost.
Avoiding these mistakes will improve both your interview performance and your production Spark code.
Conclusion
Window Functions are one of the most powerful capabilities of Spark and are heavily used in production ETL pipelines for ranking, deduplication, cumulative calculations, and analytical reporting.
Instead of memorizing individual functions, focus on understanding the business problem each Window Function solves and when it should be preferred over traditional aggregation techniques.
Once you're comfortable with the questions covered in this guide, continue with the next article in this series: Spark Transformations & Actions Interview Questions, where we'll cover lazy evaluation, narrow vs. wide transformations, actions, execution behavior, and production-focused interview scenarios.