PySpark DataFrame & Spark SQL Interview Questions
PySpark DataFrames and Spark SQL are among the most frequently tested topics in Data Engineering interviews.
Whether you are preparing for a fresher interview or an experienced Data Engineer role, you should be comfortable working with DataFrames, reading and writing files, joins, window functions, Spark SQL, and production ETL transformations.
This article is designed as a quick interview revision guide.
Instead of long explanations, you'll find:
- Topic-wise interview questions
- Important concepts to revise
- Production scenario questions
- Rapid-fire revision
- Interview preparation tips
Let's begin.
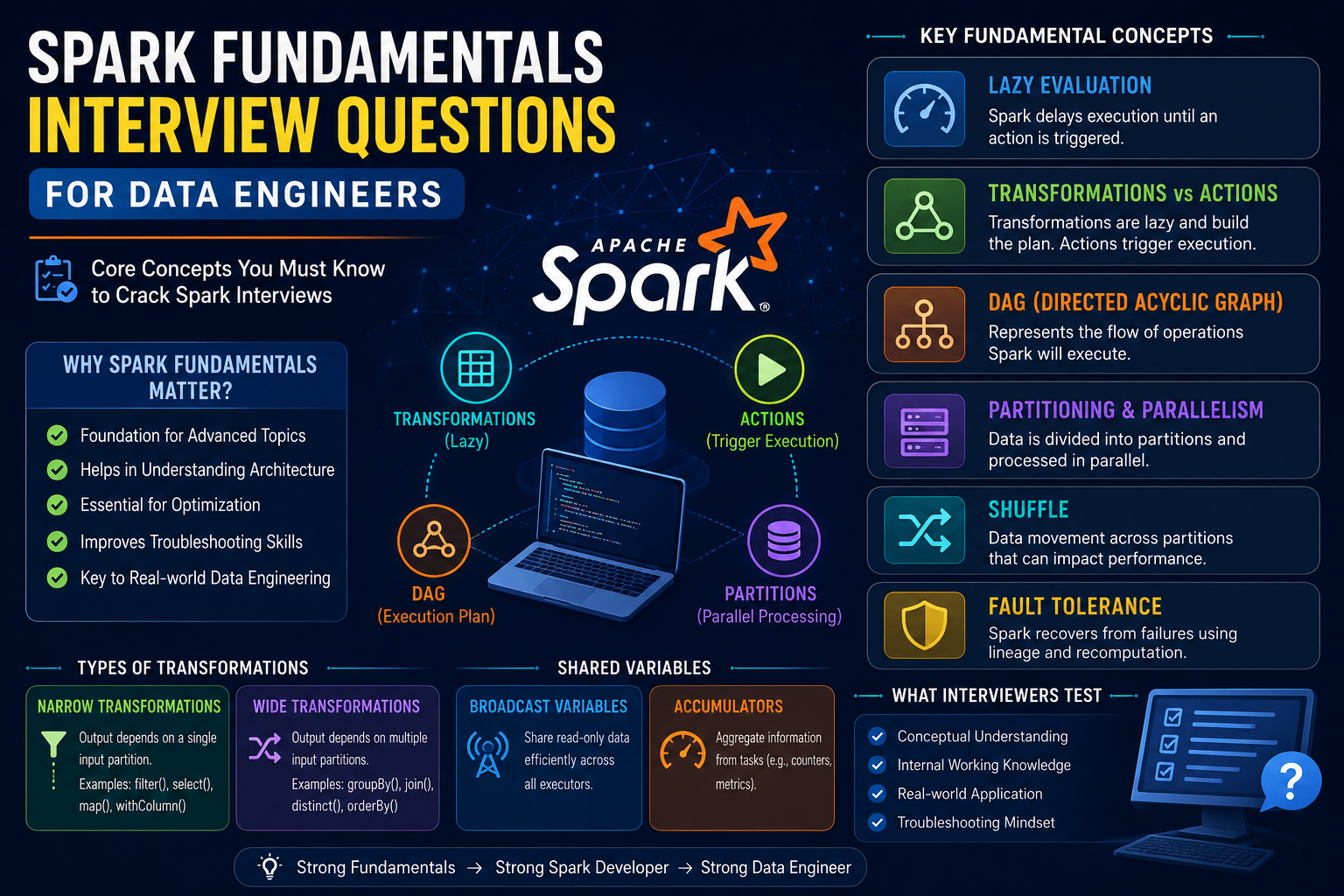
DataFrame Fundamentals Interview Questions
Questions
- What is a DataFrame in Spark?
- Difference between RDD, DataFrame and Dataset?
- Why are DataFrames faster than RDDs?
- How do you create a DataFrame?
- How do you display DataFrame contents?
- Difference between
show()andcollect()? - How do you print DataFrame schema?
- What is the difference between
printSchema()anddtypes? - How do you count records in a DataFrame?
- How do you get column names from a DataFrame?
Key Topics to Revise
- DataFrame API
- SparkSession
- Schema
- RDD vs DataFrame
- Dataset
Reading, Writing & Schema Interview Questions
Questions
- How do you read CSV files?
- How do you read Parquet files?
- Difference between CSV and Parquet?
- How do you define a custom schema?
- What happens if schema is not provided?
- What is schema inference?
- How do you write a DataFrame to Parquet?
- Difference between overwrite, append, ignore and error mode?
- What is partitionBy() while writing?
- What is bucketing?
Key Topics to Revise
- StructType
- StructField
- Schema Inference
- File Formats
- Save Modes
DataFrame Transformations Interview Questions
Questions
- Difference between
select()andwithColumn()? - Difference between
drop()anddropDuplicates()? - How do you rename columns?
- How do you filter records?
- Difference between
filter()andwhere()? - How do you sort a DataFrame?
- Difference between
orderBy()andsort()? - How do you remove duplicate rows?
- How do you create calculated columns?
- Difference between
distinct()anddropDuplicates()? - How do you explode arrays?
- What is
explode_outer()?
Key Topics to Revise
- Column Functions
- Expressions
- Explode
- Alias
- Filtering
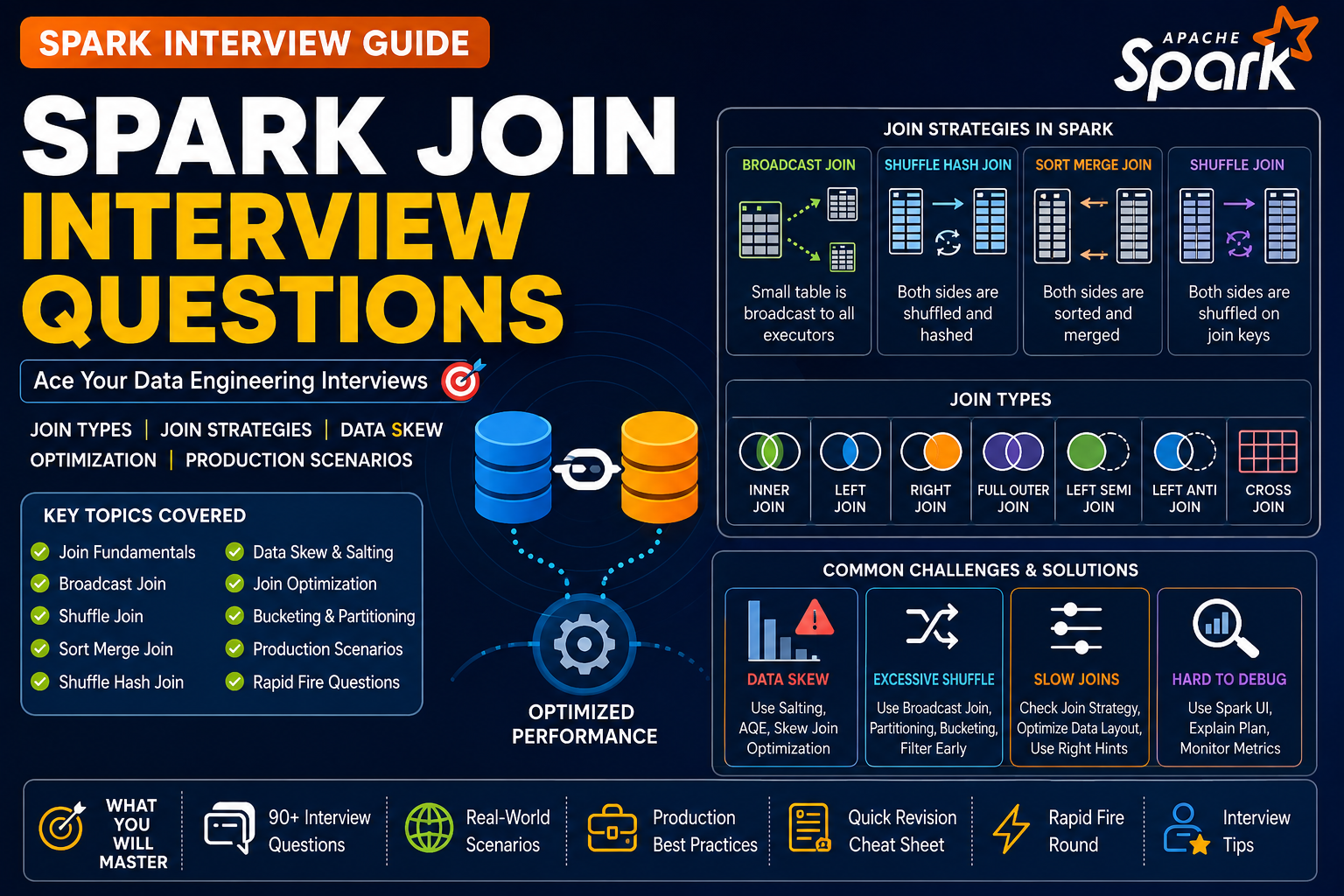
Aggregation, Window Functions & Joins Interview Questions
Questions
- What is
groupBy()? - Difference between
groupBy()andagg()? - What is a Window Function?
- Difference between
ROW_NUMBER(),RANK()andDENSE_RANK()? - What is
partitionBy()in Window Functions? - Difference between
LEAD()andLAG()? - Explain cumulative sum.
- Types of joins available in Spark.
- What is Broadcast Join?
- Difference between Broadcast Join and Shuffle Join?
- What causes shuffle during joins?
- How do you optimize joins?
- What is Data Skew?
- How do you handle skewed joins?
- Difference between
union()andunionByName()?
Key Topics to Revise
- Aggregation
- Window Specification
- Broadcast Join
- Shuffle
- Data Skew
Spark SQL Interview Questions
Questions
- What is Spark SQL?
- Difference between Spark SQL and DataFrame API?
- How do you create a temporary view?
- Difference between Temp View and Global Temp View?
- How do you execute SQL queries?
- Can Spark SQL and DataFrames be used together?
- How do you optimize Spark SQL queries?
- What is Catalyst Optimizer?
- What is Predicate Pushdown?
- What is Column Pruning?
Key Topics to Revise
- Temp View
- SQL API
- Catalyst
- Predicate Pushdown
Performance Optimization Interview Questions
Questions
- What is
cache()? - Difference between
cache()andpersist()? - When should caching be avoided?
- Difference between
repartition()andcoalesce()? - Why should
collect()be avoided? - How do you reduce shuffle?
- Why are small files bad for Spark?
- What is partition pruning?
- How do you optimize DataFrame operations?
- What metrics do you monitor in Spark UI?
Key Topics to Revise
- Cache
- Persist
- Repartition
- Coalesce
- Spark UI
Production Scenario Questions
- Input CSV has additional columns compared to your schema. How would you handle it?
- Input file has fewer columns than expected. What happens?
- How do you process nested JSON files?
- A join is taking too long. How would you optimize it?
- DataFrame contains duplicate records. How would you remove them?
- A Spark job produces thousands of small files. How would you solve it?
- Your DataFrame has millions of null values. How would you handle them?
- A UDF is slowing down the pipeline. What alternatives would you consider?
- Spark job succeeds but produces incorrect output. How would you debug it?
- Explain how you would build a production ETL pipeline using DataFrames.
Rapid Fire Questions
- RDD vs DataFrame
- DataFrame vs Dataset
- Filter vs Where
- Select vs WithColumn
- Distinct vs DropDuplicates
- Union vs UnionByName
- Cache vs Persist
- Repartition vs Coalesce
- Temp View vs Global Temp View
- Broadcast Join vs Shuffle Join
- CSV vs Parquet
- Schema Inference vs Custom Schema
- ROW_NUMBER vs RANK vs DENSE_RANK
- LEAD vs LAG
- collect() vs show()
Quick Revision Cheat Sheet
| Topic | Revise |
|---|---|
| DataFrame | Structured API |
| Schema | StructType |
| Read | CSV, JSON, Parquet |
| Write | Save Modes |
| Transform | select(), filter(), withColumn() |
| Aggregate | groupBy(), agg() |
| Window | ROW_NUMBER(), RANK(), LAG() |
| Join | Broadcast, Shuffle |
| SQL | Temp View |
| Performance | Cache, Persist, Repartition |
Interview Preparation Tips
Before attending interviews, make sure you can:
- Write DataFrame transformations without referring to documentation.
- Explain the difference between commonly used APIs.
- Handle schema-related scenarios confidently.
- Optimize joins and DataFrame transformations.
- Read and write multiple file formats.
- Use Window Functions comfortably.
- Explain production ETL scenarios using DataFrames.
Conclusion
PySpark DataFrames and Spark SQL are at the heart of modern Data Engineering pipelines.
Instead of memorizing API syntax, focus on understanding how DataFrames work, how Spark optimizes them, and how they are used in real production environments.
Once you are comfortable with the questions in this guide, move to the next article in the series: Spark Performance Optimization Interview Questions, where we'll cover shuffle optimization, memory tuning, caching, partitioning, Spark UI, AQE, and production performance tuning.