Spark Architecture Interview Questions for Data Engineers
Spark Architecture is one of the most frequently asked topics in Data Engineering interviews.
Whether you are a fresher or an experienced professional, interviewers expect you to understand how Spark executes jobs internally.
Unlike theoretical tutorials, this guide is designed as a quick interview revision resource.
Instead of lengthy explanations, you'll find:
- Topic-wise interview questions
- Important concepts to revise
- Scenario-based questions
- Rapid-fire revision
- Interview preparation tips
If you are preparing for Data Engineering interviews, completing the questions in this article will give you a strong understanding of Spark Architecture.
Driver Program Interview Questions
Questions
- What is the Driver Program in Spark?
- What are the responsibilities of the Driver?
- Does the Driver process data?
- Can Spark run without a Driver?
- What happens if the Driver crashes?
- Why can
collect()crash the Driver? - How does the Driver communicate with Executors?
- Where is SparkSession created?
- Where is SparkContext created?
- Can one Spark application have multiple Drivers?
Key Topics to Revise
- SparkSession
- SparkContext
- Driver Memory
- Job Scheduling
- Result Collection
Executor Interview Questions
Questions
- What is an Executor?
- What are the responsibilities of an Executor?
- How are Executors created?
- How many Executors can run in a Spark application?
- Can multiple Executors run on the same Worker Node?
- What happens when an Executor fails?
- How does an Executor communicate with the Driver?
- What is Executor Memory?
- What is Executor Core?
- What is Dynamic Executor Allocation?
Key Topics to Revise
- Executor Memory
- Executor Cores
- Dynamic Allocation
- Parallel Processing
- Task Execution
Worker Node Interview Questions
Questions
- What is a Worker Node?
- Difference between Worker Node and Executor?
- Can one Worker Node have multiple Executors?
- What resources does a Worker Node provide?
- What happens if a Worker Node crashes?
- How are Worker Nodes managed?
- Can Spark run with a single Worker Node?
Key Topics to Revise
- Cluster Resources
- Resource Management
- Fault Recovery
- Worker vs Executor
Cluster Manager Interview Questions
Questions
- What is a Cluster Manager?
- What are the responsibilities of a Cluster Manager?
- Difference between Driver and Cluster Manager?
- Which Cluster Managers does Spark support?
- Explain Standalone Cluster Manager.
- Explain YARN.
- Explain Kubernetes in Spark.
- Explain Apache Mesos.
- How does the Cluster Manager allocate Executors?
- Can Spark run without YARN?
Key Topics to Revise
- Standalone
- YARN
- Kubernetes
- Mesos
- Resource Allocation
Job, Stage and Task Interview Questions
Questions
- What is a Job?
- When is a Job created?
- What is a Stage?
- What is a Task?
- Difference between Job, Stage and Task?
- What creates a new Stage?
- What is a Stage Boundary?
- How are Tasks created?
- How are Tasks distributed?
- How are Partitions related to Tasks?
Key Topics to Revise
- Shuffle
- Partitions
- Parallel Processing
- Task Scheduling
- Stage Creation
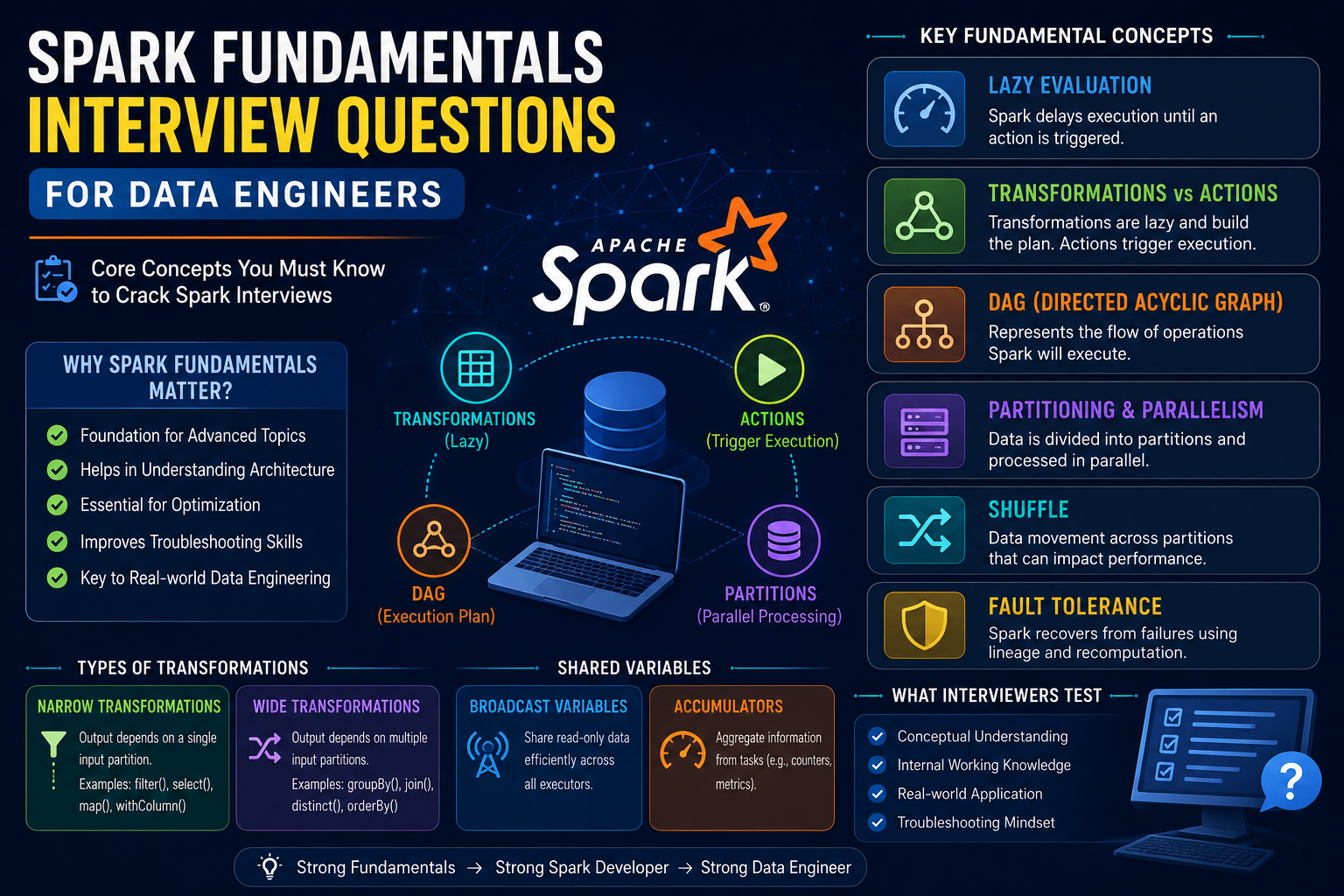
DAG and Lazy Evaluation Interview Questions
Questions
- What is DAG?
- Why is DAG important?
- How is DAG created?
- What is Lazy Evaluation?
- Why does Spark use Lazy Evaluation?
- What triggers Spark execution?
- Difference between Transformation and Action?
- How does DAG improve performance?
- Can DAG change during execution?
- What is the relationship between DAG and Stages?
Key Topics to Revise
- Transformations
- Actions
- Execution Plan
- Catalyst Optimizer
- DAG Scheduler
Spark Execution Flow Interview Questions
Questions
- Explain the complete Spark execution flow.
- What happens internally when a Spark application starts?
- What happens when an Action is triggered?
- How does the Driver create the execution plan?
- How does Spark create the DAG?
- How are Stages generated?
- How are Tasks assigned to Executors?
- How are results returned to the Driver?
- What happens during the write operation?
- Explain the complete lifecycle of a Spark Job.
Key Topics to Revise
- Driver
- DAG
- Stage Creation
- Task Scheduling
- Executors
Partitioning Interview Questions
Questions
- What is a Partition in Spark?
- Why is Partitioning important?
- How are Partitions created?
- Difference between Logical and Physical Partitions?
- What happens if there are too many Partitions?
- What happens if there are too few Partitions?
- Difference between
repartition()andcoalesce()? - What is Partition Pruning?
- How do Partitions improve parallelism?
- How do you decide the optimal number of Partitions?
Key Topics to Revise
- Parallel Processing
- Shuffle
- Partition Pruning
- Repartition
- Coalesce
Fault Tolerance Interview Questions
Questions
- What is Fault Tolerance?
- How does Spark recover from failures?
- What is Lineage?
- How does Lineage help Spark?
- What happens if an Executor fails?
- What happens if a Worker Node crashes?
- What happens if a Task fails?
- What is Task Retry?
- What is Speculative Execution?
- How does Spark recover lost Partitions?
Key Topics to Revise
- DAG
- Lineage
- Retry Mechanism
- Speculative Execution
- Executor Failure
Catalyst Optimizer, Tungsten & AQE Interview Questions
Questions
- What is Catalyst Optimizer?
- What are the phases of Catalyst Optimizer?
- What is Tungsten Engine?
- Why was Project Tungsten introduced?
- Difference between Catalyst and Tungsten?
- What is Adaptive Query Execution (AQE)?
- How does AQE improve Spark performance?
- How does AQE handle Data Skew?
- How does AQE optimize Shuffle?
- Is AQE enabled by default?
Key Topics to Revise
- Query Optimization
- Execution Plan
- Whole Stage Code Generation
- Runtime Optimization
- Spark SQL
Parallel Processing Interview Questions
Questions
- What is Parallel Processing?
- How does Spark process data in parallel?
- What is Task Parallelism?
- What is Data Parallelism?
- What limits parallel execution?
- How are CPU Cores utilized in Spark?
- Why is Spark faster than traditional processing engines?
- How do Executors process multiple Tasks?
- What is the relationship between Partitions and Parallelism?
- How do you increase parallelism in Spark?
Key Topics to Revise
- Executors
- CPU Cores
- Partitions
- Tasks
- Scheduling
Spark Architecture Production Scenario Questions
These are some of the most frequently asked real-world scenario questions.
-
Your Spark application suddenly became very slow. How would you investigate?
-
The Driver is running out of memory. What could be the possible reasons?
-
Executors keep failing randomly. How would you debug the issue?
-
Spark creates too many Stages. What could be causing this?
-
One Task is taking much longer than all the others. What might be happening?
-
An entire Worker Node crashes during execution. How does Spark recover?
-
Spark UI shows a huge Shuffle Read size. What would you investigate first?
-
Your Spark job is processing only a few Tasks even though the cluster has many Executors. Why?
-
A Spark job succeeds but produces incorrect output. How would you debug it?
-
Explain the complete Spark Architecture using a real ETL pipeline processing millions of records daily.
Spark Architecture Rapid Fire Questions
Quickly revise these before your interview.
- Driver vs Executor
- Driver vs Cluster Manager
- Worker Node vs Executor
- Job vs Stage vs Task
- Partition vs Task
- Transformation vs Action
- Narrow vs Wide Transformation
- DAG vs Execution Plan
- SparkSession vs SparkContext
- Repartition vs Coalesce
- Catalyst vs Tungsten
- AQE vs Static Optimization
- Fault Tolerance vs Lineage
- Shuffle vs Broadcast
- Static Allocation vs Dynamic Allocation
Quick Revision Cheat Sheet
| Concept | Remember |
|---|---|
| Driver | Coordinates the Spark application |
| Executor | Executes Tasks |
| Worker Node | Machine hosting Executors |
| Cluster Manager | Allocates cluster resources |
| Job | Created by an Action |
| Stage | Group of Tasks separated by Shuffle |
| Task | Smallest execution unit |
| Partition | Chunk of Data |
| DAG | Execution Plan |
| Lazy Evaluation | Delayed execution until Action |
| Lineage | Recovery mechanism |
| Catalyst | Query Optimizer |
| Tungsten | Execution Engine |
| AQE | Runtime Query Optimization |
Interview Preparation Tips
Before attending a Spark interview, make sure you can confidently explain:
- Complete Spark Architecture
- Driver, Executor, Worker Node, and Cluster Manager
- Job → Stage → Task hierarchy
- DAG creation and execution
- Lazy Evaluation
- Transformations vs Actions
- Partitioning and Parallel Processing
- Fault Tolerance and Lineage
- Catalyst Optimizer, Tungsten, and AQE
- End-to-end Spark execution flow without referring to notes
A good exercise is to draw the Spark Architecture on paper and explain each component in your own words. This will help you answer both direct and scenario-based interview questions with confidence.
Conclusion
Spark Architecture forms the foundation of almost every Data Engineering interview. If you understand how Spark distributes work, schedules tasks, manages resources, and recovers from failures, you will be well prepared for both technical discussions and production scenario questions.
Use this guide as a revision checklist rather than trying to memorize answers. Once you are comfortable with these questions, move on to the next article in this series: PySpark DataFrame & Spark SQL Interview Questions, where we'll cover DataFrames, Schema Handling, Window Functions, UDFs, Joins, and real-world transformation scenarios.