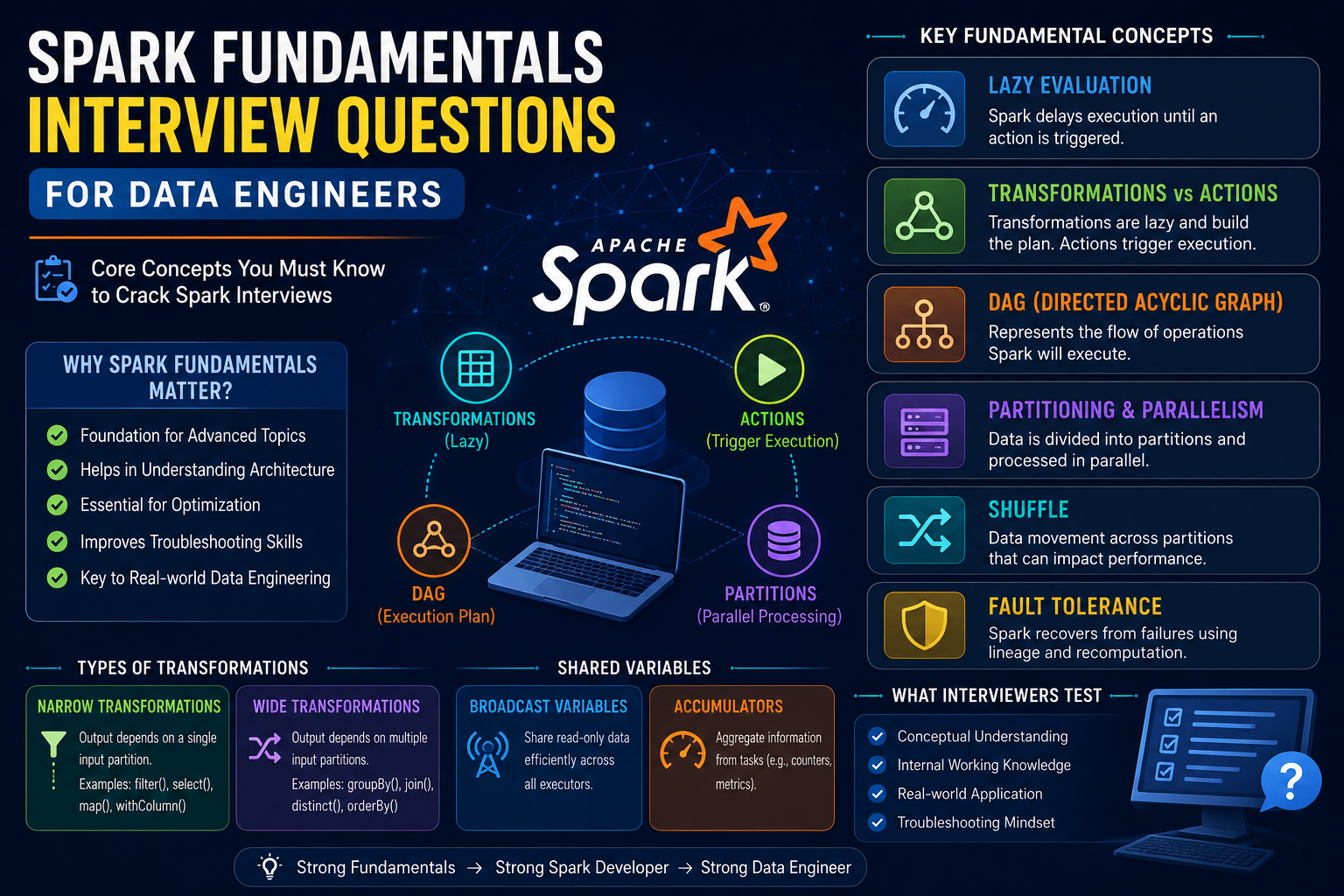
Spark Transformations & Actions Interview Questions
Spark Transformations and Actions are the foundation of every Spark application. Whether you're processing millions of records or building enterprise-scale ETL pipelines, every Spark job is a combination of transformations and actions.
Although these concepts appear simple, they are among the most frequently asked topics in Spark interviews because they explain how Spark executes code internally.
Interviewers often ask questions such as:
- What is the difference between a Transformation and an Action?
- What is Lazy Evaluation?
- Why doesn't Spark execute transformations immediately?
- What is a Narrow Transformation?
- What is a Wide Transformation?
- What happens internally when an Action is triggered?
- How does Spark create a DAG?
This guide is designed as a quick interview revision resource.
Instead of lengthy explanations, you'll find:
- Topic-wise interview questions
- Important concepts to revise
- Production scenario questions
- Rapid-fire revision
- Interview preparation tips
Let's get started.
Transformation Fundamentals Interview Questions
Questions
- What is a Transformation in Spark?
- Why are Transformations called lazy operations?
- What are the different types of Transformations?
- How do Transformations create new DataFrames?
- Why are Transformations immutable?
- Does a Transformation execute immediately?
- What happens internally after applying a Transformation?
- Can multiple Transformations be chained together?
- What is the advantage of chaining Transformations?
- Which Spark component manages Transformations?
- How do Transformations contribute to DAG creation?
- Give examples of commonly used Transformations.
Key Topics to Revise
- Lazy Evaluation
- Immutability
- DAG
- Logical Plan
- DataFrame API
Action Fundamentals Interview Questions
Questions
- What is an Action in Spark?
- Why are Actions required?
- What happens when an Action is triggered?
- Which operations are considered Actions?
- Difference between
show()andcollect()? - Difference between
count()andtake()? - Why is
collect()considered dangerous? - What happens if multiple Actions are executed on the same DataFrame?
- Does every Action create a new Job?
- Can an Action trigger multiple Stages?
- What happens if an Action fails?
- How do Actions interact with the Driver Program?
Key Topics to Revise
- Driver
- Job
- Stage
- Task
- Spark Execution
Lazy Evaluation Interview Questions
Questions
- What is Lazy Evaluation?
- Why does Spark use Lazy Evaluation?
- What are the advantages of Lazy Evaluation?
- When does Spark actually execute Transformations?
- How does Lazy Evaluation improve performance?
- What happens internally before an Action is executed?
- How does Spark optimize multiple Transformations?
- What role does Catalyst Optimizer play in Lazy Evaluation?
- How is Lazy Evaluation related to DAG?
- Can Lazy Evaluation reduce unnecessary computations?
- What are the limitations of Lazy Evaluation?
- Explain Lazy Evaluation using a real-world example.
Key Topics to Revise
- Catalyst Optimizer
- DAG
- Logical Plan
- Physical Plan
- Execution Trigger
Narrow Transformation Interview Questions
Questions
- What is a Narrow Transformation?
- Why are Narrow Transformations faster?
- Which operations are Narrow Transformations?
- Does a Narrow Transformation trigger Shuffle?
- How does Spark execute Narrow Transformations?
- Difference between Narrow and Wide Transformations?
- Why are Narrow Transformations preferred?
- How do Narrow Transformations improve performance?
- Can multiple Narrow Transformations execute within the same Stage?
- Give real-world examples of Narrow Transformations.
- Why are
filter()andselect()considered Narrow Transformations? - Which ETL operations commonly use Narrow Transformations?
Key Topics to Revise
- Filter
- Select
- Map
- FlatMap
- Stage Execution
Wide Transformation Interview Questions
Questions
- What is a Wide Transformation?
- Why are Wide Transformations expensive?
- Which operations are Wide Transformations?
- Why do Wide Transformations trigger Shuffle?
- How do Wide Transformations create new Stages?
- Difference between
groupBy()andfilter()from Spark's execution perspective? - Why are joins considered Wide Transformations?
- How do Wide Transformations impact network I/O?
- How do Wide Transformations affect Spark performance?
- Which ETL operations commonly involve Wide Transformations?
- How do you optimize Wide Transformations?
- How can excessive Wide Transformations slow down a Spark job?
Key Topics to Revise
- Shuffle
- groupBy
- join
- repartition
- Stage Boundary
DAG & Lineage Interview Questions
Questions
- What is a DAG in Spark?
- Why does Spark create a DAG?
- What is Lineage in Spark?
- How does Lineage help in fault tolerance?
- Difference between DAG and Lineage?
- What happens if an Executor fails?
- How does Spark recover lost partitions?
- What is the relationship between DAG and Lazy Evaluation?
- How do Transformations build the DAG?
- How do Actions trigger DAG execution?
- How do you visualize the DAG?
- Why is understanding DAG important for optimization?
Key Topics to Revise
- DAG
- Lineage
- Fault Tolerance
- Spark UI
- Execution Plan
Execution Flow Interview Questions
Questions
- What happens internally when a Spark application starts?
- What happens after an Action is triggered?
- How does Spark convert Transformations into a DAG?
- How does Catalyst Optimizer optimize the execution plan?
- What is the difference between a Logical Plan and a Physical Plan?
- How are Jobs, Stages, and Tasks created?
- What causes a new Stage in Spark?
- How are Tasks distributed across Executors?
- How does Spark execute multiple Transformations efficiently?
- What role does the Driver play during execution?
- How do Executors process Tasks?
- How do you analyze execution flow using Spark UI?
Key Topics to Revise
- Driver
- Executors
- DAG
- Logical Plan
- Physical Plan
- Jobs
- Stages
- Tasks
Production Scenario Questions
These are some of the most commonly asked production-based Spark Transformations & Actions interview questions.
-
A Spark job is running successfully but taking much longer than expected. How would you identify whether the issue is caused by a Wide Transformation?
-
A developer has used multiple
collect()operations in a Spark application. What problems could this create? -
Your ETL pipeline contains dozens of chained Transformations. How does Spark optimize their execution?
-
A Spark application is failing with
OutOfMemoryExceptionafter callingcollect(). How would you resolve it? -
How would you explain Lazy Evaluation to a team member who is new to Spark?
-
A pipeline contains several
groupBy()andjoin()operations. What performance issues would you expect? -
Your Spark UI shows many Stages for a relatively small job. What could be the reason?
-
A Spark job contains only Narrow Transformations. What execution behavior would you expect?
-
A DataFrame is used multiple times in different Actions. How would you optimize the application?
-
Explain the complete execution flow from reading a file to writing the final output.
-
How would you identify unnecessary Actions in a Spark application?
-
What happens if an Executor fails during execution?
-
How does Spark recover from failed Tasks?
-
What would you monitor in Spark UI to understand execution performance?
-
Explain a real production ETL pipeline where understanding Transformations and Actions helped optimize performance.
Spark Transformations & Actions Rapid Fire Questions
Quickly revise these concepts before your interview.
- Transformation vs Action
- Lazy Evaluation vs Immediate Execution
- Narrow vs Wide Transformation
- Logical Plan vs Physical Plan
- DAG vs Lineage
- Job vs Stage
- Stage vs Task
- Driver vs Executor
show()vscollect()count()vstake()filter()vsgroupBy()select()vsjoin()map()vsflatMap()repartition()vscoalesce()cache()vspersist()
Quick Revision Cheat Sheet
| Topic | Remember |
|---|---|
| Transformation | Lazy operation that creates a new DataFrame/RDD |
| Action | Triggers Spark execution |
| Lazy Evaluation | Execution starts only after an Action |
| Narrow Transformation | No Shuffle required |
| Wide Transformation | Requires Shuffle |
| DAG | Execution graph built by Spark |
| Lineage | Tracks data transformations for fault tolerance |
| Job | Created when an Action is executed |
| Stage | Group of Tasks separated by Shuffle boundaries |
| Task | Smallest unit of execution |
| Driver | Coordinates the Spark application |
| Executor | Executes Tasks on worker nodes |
Interview Preparation Tips
Before attending Spark interviews, ensure you can confidently explain:
- The difference between Transformations and Actions.
- Why Spark uses Lazy Evaluation.
- The difference between Narrow and Wide Transformations.
- How DAGs are created and executed.
- The relationship between Jobs, Stages, and Tasks.
- How Lineage enables fault tolerance.
- Why
collect()should be used carefully. - How multiple Transformations are optimized before execution.
- How to analyze execution flow using Spark UI.
- Real-world scenarios where execution behavior impacts performance.
A great way to prepare is to write a simple Spark program, predict how many Jobs and Stages will be created, and then verify your understanding using the Spark UI. This exercise helps bridge the gap between theory and real-world execution.
Common Mistakes Candidates Make
Many candidates know the syntax of Spark Transformations but struggle to explain what happens internally.
Some common mistakes include:
- Assuming every Transformation executes immediately.
- Confusing Transformations with Actions.
- Not understanding why
collect()can crash the Driver. - Mixing up Narrow and Wide Transformations.
- Ignoring the role of Lazy Evaluation.
- Forgetting that every Action creates a new Job.
- Assuming every Transformation creates a new Stage.
- Not understanding how Shuffle affects execution.
- Confusing DAG with Lineage.
- Relying on memorized definitions instead of understanding Spark's execution flow.
Avoiding these mistakes will help you answer follow-up interview questions with confidence and design more efficient Spark applications.
Conclusion
Transformations and Actions form the foundation of every Spark application. A solid understanding of these concepts helps you write efficient Spark code, interpret Spark UI correctly, optimize ETL pipelines, and troubleshoot production issues.
Instead of memorizing definitions, focus on understanding how Spark builds the execution plan, when execution begins, and why certain operations are more expensive than others.
Once you're comfortable with the topics covered in this guide, continue with the next article in this series: Spark Structured Streaming Interview Questions, where we'll explore micro-batches, triggers, checkpoints, watermarks, stateful processing, fault tolerance, and production-focused interview scenarios.