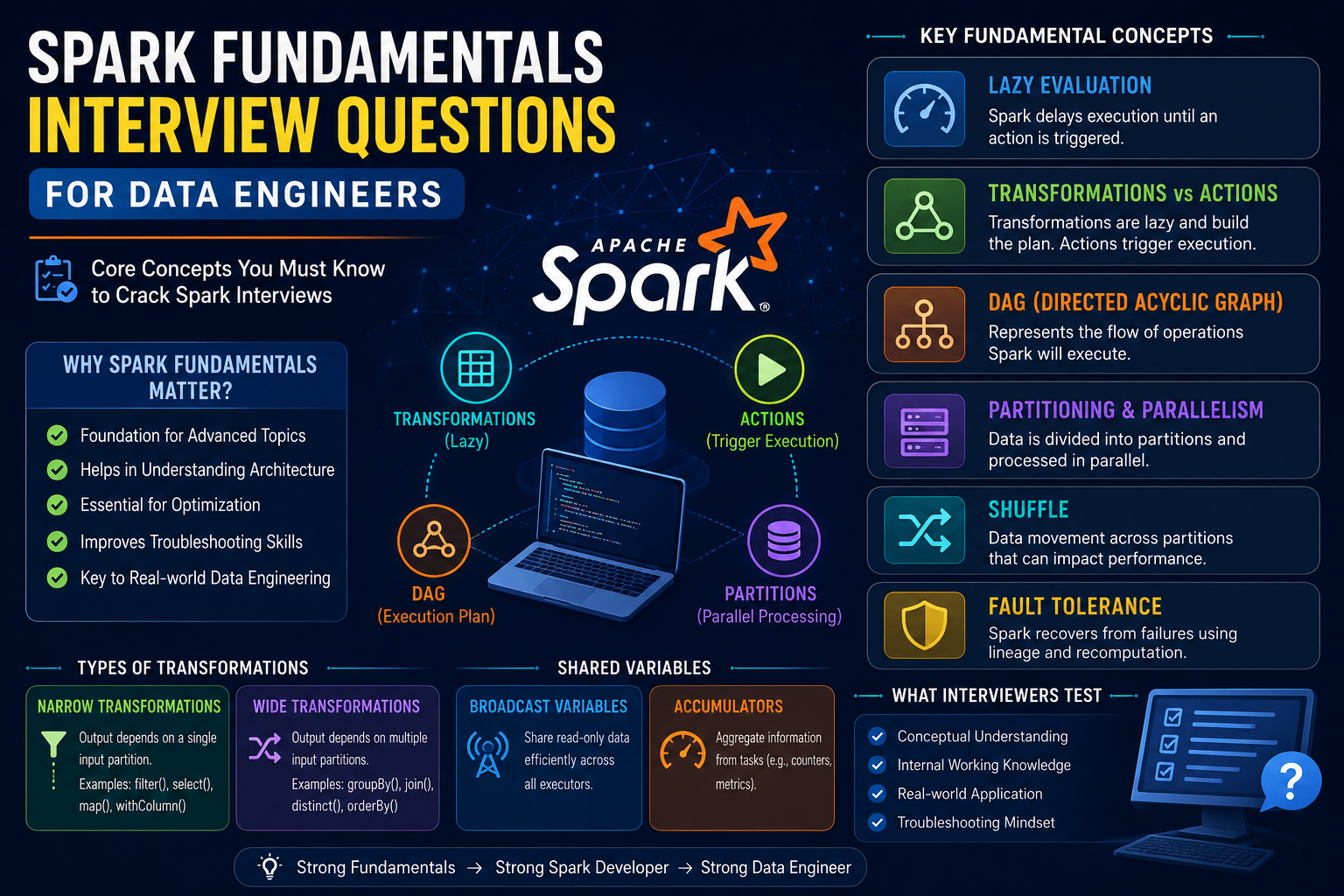
Spark Join Interview Questions for Data Engineers
Spark Joins are one of the most frequently discussed topics in Data Engineering interviews because almost every production ETL pipeline combines data from multiple sources.
Whether you are joining customer data with orders, products with sales, or transactions with reference data, understanding how Spark performs joins is essential for writing efficient and scalable data pipelines.
Interviewers usually don't stop at asking:
"What is an Inner Join?"
Instead, they ask questions like:
- Which join strategy is the fastest?
- What causes Shuffle during joins?
- When should Broadcast Join be used?
- How do you optimize joins processing billions of records?
- How do you handle Data Skew?
This guide is designed as a quick interview revision resource.
Instead of lengthy explanations, you'll find:
- Topic-wise interview questions
- Important concepts to revise
- Production scenario questions
- Rapid-fire revision
- Interview preparation tips
Let's get started.
Join Fundamentals Interview Questions
Questions
- What is a Join in Spark?
- Why are joins required in Data Engineering?
- What are the different types of joins available in Spark?
- How does Spark perform joins internally?
- Why are joins considered expensive operations?
- Which factors affect join performance?
- Which Spark component executes joins?
- Why can joins become a bottleneck in ETL pipelines?
- How does Spark choose a join strategy?
- What should you verify before joining two DataFrames?
- What happens if join keys contain duplicate values?
- How do partitions impact join performance?
Key Topics to Revise
- Spark Execution
- Partitions
- Shuffle
- Catalyst Optimizer
- Execution Plan
Types of Join Interview Questions
Questions
- Explain Inner Join.
- Explain Left Join.
- Explain Right Join.
- Explain Full Outer Join.
- Explain Cross Join.
- Explain Left Semi Join.
- Explain Left Anti Join.
- Difference between Inner Join and Left Join?
- Difference between Left Join and Left Semi Join?
- Difference between Left Join and Left Anti Join?
- When should Cross Join be avoided?
- Which join usually performs the fastest?
- Which join is generally the most expensive?
- Which joins can generate large Shuffle?
- Which join type is commonly used in ETL pipelines?
Key Topics to Revise
- Join Types
- Join Conditions
- Join Keys
- Cartesian Product
- Null Handling
Broadcast Join Interview Questions
Questions
- What is a Broadcast Join?
- Why is Broadcast Join faster than Shuffle Join?
- When should Broadcast Join be used?
- How does Spark perform a Broadcast Join internally?
- How do you force a Broadcast Join?
- How does Spark automatically choose Broadcast Join?
- What is
spark.sql.autoBroadcastJoinThreshold? - What happens if the broadcast table is too large?
- Can AQE automatically convert a Shuffle Join into a Broadcast Join?
- What are the limitations of Broadcast Join?
- Why should large tables never be broadcast?
- How do you verify a Broadcast Join using Spark UI?
- How do you disable automatic Broadcast Join?
- What are common production use cases for Broadcast Join?
- Explain Broadcast Join with a real-world customer lookup example.
Key Topics to Revise
- Broadcast Variables
- Broadcast Threshold
- AQE
- Spark SQL
- Explain Plan
Shuffle Join Interview Questions
Questions
- What is a Shuffle Join?
- Why does Shuffle occur during joins?
- Why is Shuffle considered expensive?
- Difference between Broadcast Join and Shuffle Join?
- Which join operations trigger Shuffle?
- What is Shuffle Read?
- What is Shuffle Write?
- How do you identify Shuffle in Spark UI?
- How do you reduce Shuffle during joins?
- Can proper partitioning reduce Shuffle?
- How does network transfer impact Shuffle performance?
- How do file formats affect Shuffle performance?
Key Topics to Revise
- Shuffle Read
- Shuffle Write
- Stage Boundaries
- Network I/O
- Spark UI
Sort Merge Join Interview Questions
Questions
- What is Sort Merge Join?
- Why is Sort Merge Join Spark's default join strategy?
- When does Spark choose Sort Merge Join?
- Difference between Sort Merge Join and Broadcast Join?
- Difference between Sort Merge Join and Shuffle Hash Join?
- What are the advantages of Sort Merge Join?
- What are the disadvantages of Sort Merge Join?
- Why is sorting required before merging?
- How can Sort Merge Join performance be improved?
- How do you verify Sort Merge Join in the execution plan?
Key Topics to Revise
- Sorting
- Merge Phase
- Explain Plan
- AQE
- Shuffle
Shuffle Hash Join Interview Questions
Questions
- What is Shuffle Hash Join?
- When does Spark choose Shuffle Hash Join?
- Difference between Shuffle Hash Join and Sort Merge Join?
- What are the advantages of Shuffle Hash Join?
- What are the limitations of Shuffle Hash Join?
- Why is Shuffle Hash Join less common than Sort Merge Join?
- Can AQE switch to Shuffle Hash Join?
- Which datasets are suitable for Shuffle Hash Join?
- How do you identify Shuffle Hash Join in Spark UI?
- Which join strategy performs better for medium-sized datasets?
Key Topics to Revise
- Hash Join
- AQE
- Shuffle
- Explain Plan
- Memory Usage
Data Skew Interview Questions
Questions
- What is Data Skew in Spark?
- Why does Data Skew occur during joins?
- How do you identify Data Skew?
- How do you identify Data Skew using Spark UI?
- What are the symptoms of Data Skew?
- Why does one Executor take much longer than others?
- How does Data Skew affect Spark performance?
- How do you handle skewed joins?
- What is Salting in Spark?
- How does Salting help reduce Data Skew?
- Can AQE automatically handle Data Skew?
- What is Skew Join Optimization?
- What is the difference between skewed partitions and uneven partitions?
- How do you prevent Data Skew during ETL design?
- Explain a real-world example of Data Skew.
Key Topics to Revise
- Data Skew
- Salting
- AQE
- Skew Join
- Spark UI
Join Optimization Interview Questions
Questions
- How do you optimize joins in Spark?
- Which join strategy provides the best performance?
- When should Broadcast Join be preferred?
- How do you reduce Shuffle during joins?
- How does partitioning improve join performance?
- How does bucketing improve joins?
- What is Predicate Pushdown?
- What is Column Pruning?
- Why should unnecessary columns be removed before joins?
- Why should filters be applied before joins?
- How do you optimize joins on TB-scale datasets?
- How do file formats impact join performance?
- How does AQE optimize joins?
- How do you optimize joins in Databricks?
- What metrics do you monitor while tuning joins?
Key Topics to Revise
- Broadcast Join
- Partitioning
- Bucketing
- AQE
- Spark UI
Bucketing & Partitioning Interview Questions
Questions
- What is Bucketing in Spark?
- Difference between Partitioning and Bucketing?
- When should Bucketing be used?
- How does Bucketing improve joins?
- What are the limitations of Bucketing?
- Can Partitioning completely replace Bucketing?
- How does Partition Pruning improve performance?
- Which columns should be selected for Partitioning?
- Which columns should be selected for Bucketing?
- When should Partitioning be avoided?
Key Topics to Revise
- Bucketing
- Partitioning
- Partition Pruning
- File Layout
- Join Performance
Production Scenario Questions
These are some of the most commonly asked production-based Spark Join interview questions.
-
Two large DataFrames are taking a long time to join. How would you optimize the join?
-
Your Spark UI shows excessive Shuffle Read during joins. What would you investigate first?
-
A small lookup table is being joined with a very large fact table. Which join strategy would you choose?
-
One Executor is processing significantly more data than the others during a join. What could be the reason?
-
A join query is running successfully but taking much longer in production than in development. How would you troubleshoot it?
-
Your join output contains duplicate records. What would you investigate?
-
A Broadcast Join is causing Executor OutOfMemory errors. What could be the possible reason?
-
Your Spark application creates thousands of small files after a join. How would you resolve this issue?
-
AQE is enabled, but the join is still slow. What additional optimizations would you consider?
-
Explain how you would join a 20 GB customer master table with a 5 TB sales transaction table.
-
Explain your approach for joining multiple large DataFrames in a production ETL pipeline.
-
How would you debug an intermittent join failure in production?
-
What metrics do you monitor in Spark UI during join optimization?
-
Explain a production incident where Data Skew affected join performance and how you would resolve it.
-
How do you design joins for scalable daily ETL pipelines?
Spark Join Rapid Fire Questions
Quickly revise these before your interview.
- Inner Join vs Left Join
- Left Join vs Left Semi Join
- Left Join vs Left Anti Join
- Broadcast Join vs Shuffle Join
- Sort Merge Join vs Shuffle Hash Join
- Shuffle Read vs Shuffle Write
- Data Skew vs Uneven Partitioning
- Partitioning vs Bucketing
- AQE vs Static Join Planning
- Predicate Pushdown vs Column Pruning
- Broadcast Threshold
- Salting vs Repartitioning
- Explain Plan vs Spark UI
- Join Optimization vs Query Optimization
- Broadcast Hint vs Auto Broadcast
Quick Revision Cheat Sheet
| Topic | Remember |
|---|---|
| Broadcast Join | Best for small lookup tables |
| Shuffle Join | Used for large datasets |
| Sort Merge Join | Default join strategy |
| Shuffle Hash Join | Suitable for medium-sized datasets |
| Data Skew | Uneven data distribution |
| Salting | Technique to reduce skew |
| AQE | Runtime join optimization |
| Bucketing | Reduces shuffle for repeated joins |
| Partitioning | Improves parallelism |
| Predicate Pushdown | Reads only required rows |
| Column Pruning | Reads only required columns |
| Explain Plan | Shows physical execution strategy |
| Spark UI | Primary performance debugging tool |
Interview Preparation Tips
Before attending Spark interviews, make sure you can confidently explain:
- Every Spark join type and when to use it.
- Differences between Broadcast Join, Shuffle Join, Sort Merge Join, and Shuffle Hash Join.
- Why Shuffle occurs and how to reduce it.
- How to identify and resolve Data Skew.
- The difference between Partitioning and Bucketing.
- How AQE optimizes joins at runtime.
- How to analyze join performance using Spark UI.
- Real-world ETL scenarios involving large-scale joins.
- Common join optimization techniques used in production.
A good exercise is to take a real-world ETL pipeline and identify where different join strategies would be most appropriate. This practical thinking is often what interviewers expect from experienced Data Engineers.
Conclusion
Joins are one of the most important building blocks of Spark-based ETL pipelines. Understanding different join strategies, recognizing performance bottlenecks, and applying the right optimization techniques are essential skills for every Data Engineer.
Instead of memorizing definitions, focus on understanding when to use each join strategy, why Spark chooses a particular execution plan, and how to troubleshoot join performance issues in production.
Once you're comfortable with the topics covered in this guide, continue with the next article in this series: Spark Window Functions Interview Questions, where we'll cover ranking functions, analytical functions, cumulative calculations, optimization techniques, and production-focused interview scenarios.