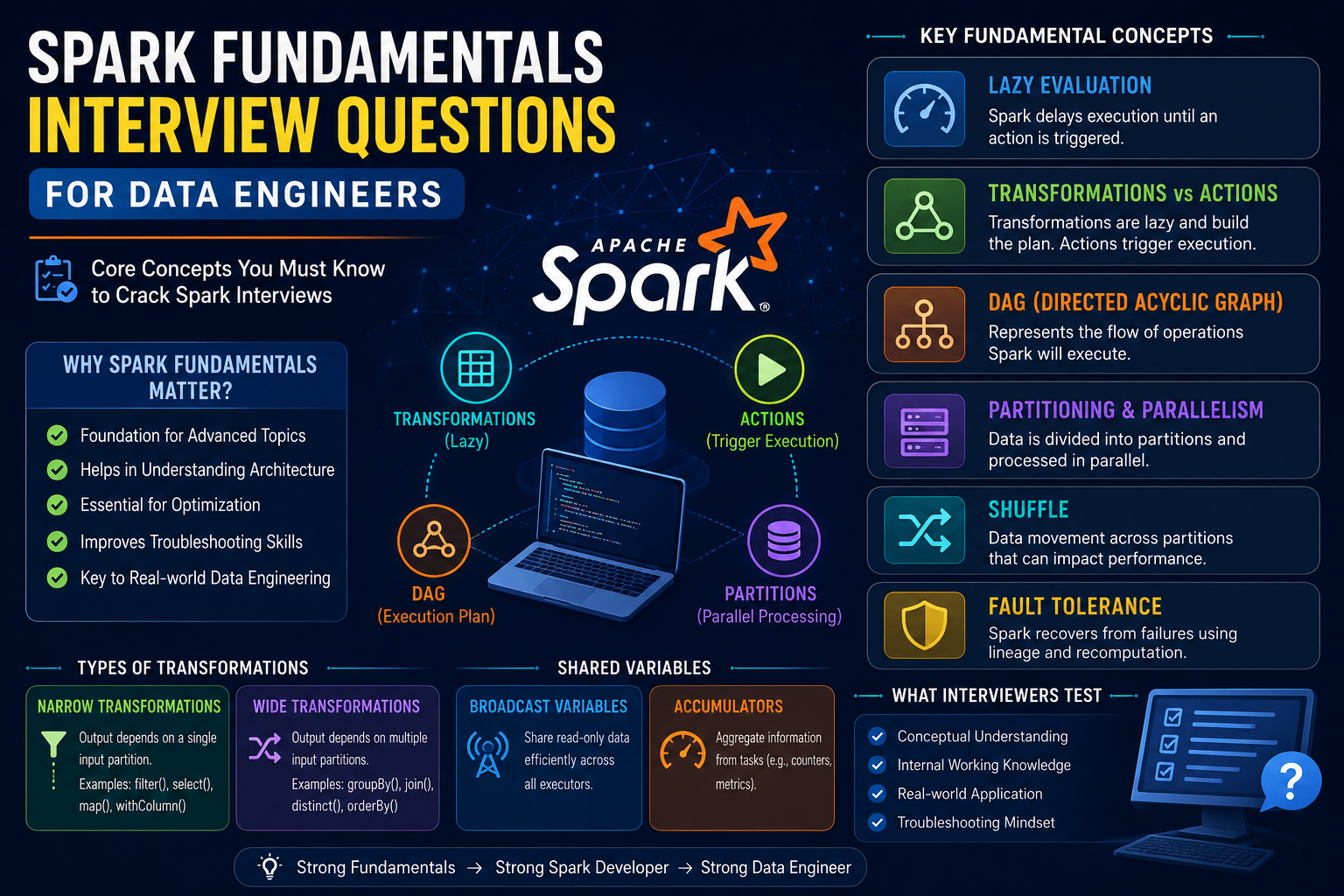
Spark Performance Optimization Interview Questions
Spark Performance Optimization is one of the most important topics in Data Engineering interviews.
Many candidates know how to write PySpark code, but interviewers often focus on a different question:
Can you optimize Spark jobs for production?
Whether you are interviewing for a Data Engineer, Big Data Engineer, or PySpark Developer role, you should understand concepts like shuffle, partitioning, caching, joins, Spark UI, memory tuning, and Adaptive Query Execution (AQE).
This guide is designed as a quick interview revision resource.
Instead of lengthy explanations, you'll find:
- Topic-wise interview questions
- Important concepts to revise
- Production scenario questions
- Rapid-fire revision
- Interview preparation tips
Let's get started.
Shuffle Interview Questions
Questions
- What is Shuffle in Spark?
- Why is Shuffle considered expensive?
- Which operations trigger a Shuffle?
- How do you identify Shuffle in Spark UI?
- How do you reduce Shuffle?
- What is Shuffle Read?
- What is Shuffle Write?
- How does Shuffle impact performance?
- How do joins create Shuffle?
- How does
groupBy()create Shuffle? - Difference between Narrow and Wide Transformations?
- Which transformations avoid Shuffle?
Key Topics to Revise
- Wide Transformations
- Shuffle Read
- Shuffle Write
- Network I/O
- Stage Boundaries
Partitioning Interview Questions
Questions
- What is Partitioning in Spark?
- Why is Partitioning important?
- How are Partitions created?
- Difference between Logical and Physical Partitions?
- What happens if there are too many Partitions?
- What happens if there are too few Partitions?
- Difference between
repartition()andcoalesce()? - What is Partition Pruning?
- How do Partitions improve parallelism?
- How do you decide the optimal number of Partitions?
- What is Data Skew?
- How does skewed Partitioning affect performance?
Key Topics to Revise
- Repartition
- Coalesce
- Parallelism
- Data Skew
- Partition Pruning
Cache & Persist Interview Questions
Questions
- What is
cache()in Spark? - What is
persist()? - Difference between
cache()andpersist()? - When should caching be used?
- When should caching be avoided?
- What are different Storage Levels?
- What happens if cached data doesn't fit into memory?
- Does Spark automatically remove cached data?
- How do you clear cached data?
- Can caching improve iterative algorithms?
Key Topics to Revise
- MEMORY_ONLY
- MEMORY_AND_DISK
- Storage Levels
- Cache Management
- Persist
Join Optimization Interview Questions
Questions
- What is Broadcast Join?
- When should Broadcast Join be used?
- Difference between Broadcast Join and Shuffle Join?
- What is Sort Merge Join?
- What is Shuffle Hash Join?
- What causes Data Skew during joins?
- How do you optimize joins in Spark?
- Which join usually performs the best?
- How does AQE optimize joins?
- What happens internally during a join?
- Why are joins expensive?
- How do you identify slow joins in Spark UI?
Key Topics to Revise
- Broadcast Join
- Shuffle Join
- Sort Merge Join
- AQE
- Data Skew
File Format Optimization Interview Questions
Questions
- Why is Parquet preferred over CSV?
- Difference between Parquet and ORC?
- Why should Avro be used?
- Which file format is best for analytical workloads?
- How do columnar file formats improve performance?
- What is Predicate Pushdown?
- What is Column Pruning?
- Why are small files considered a performance issue?
- What is File Compaction?
- How do Iceberg and Delta Lake help optimize file management?
Key Topics to Revise
- Parquet
- ORC
- Avro
- Predicate Pushdown
- File Compaction
Spark UI Interview Questions
Questions
- What is Spark UI?
- What information does Spark UI provide?
- How do you identify slow Stages?
- How do you identify slow Tasks?
- How do you detect Data Skew in Spark UI?
- What is Executor Tab?
- What is Storage Tab?
- What is SQL Tab?
- What metrics should be monitored in Spark UI?
- How do you use Spark UI for performance tuning?
Key Topics to Revise
- Jobs Tab
- Stages Tab
- Executors Tab
- SQL Tab
- Storage Tab
Memory Management Interview Questions
Questions
- How does Spark manage memory?
- What is Executor Memory?
- What is Driver Memory?
- What causes
OutOfMemoryExceptionin Spark? - How do you troubleshoot memory-related failures?
- What is Memory Fraction in Spark?
- Difference between Storage Memory and Execution Memory?
- How does Garbage Collection affect Spark performance?
- How do you tune Executor Memory?
- How do you optimize memory usage for large datasets?
Key Topics to Revise
- Executor Memory
- Driver Memory
- Storage Memory
- Execution Memory
- Garbage Collection
Adaptive Query Execution (AQE) Interview Questions
Questions
- What is Adaptive Query Execution (AQE)?
- Why was AQE introduced?
- How does AQE improve Spark performance?
- How does AQE optimize joins?
- How does AQE handle Data Skew?
- How does AQE optimize Shuffle Partitions?
- Difference between static optimization and AQE?
- Is AQE enabled by default?
- What are the limitations of AQE?
- When should AQE be disabled?
Key Topics to Revise
- Runtime Optimization
- Broadcast Join
- Shuffle Optimization
- Data Skew
- Spark SQL
Performance Tuning Production Scenario Questions
These are some of the most commonly asked production-based Spark optimization questions.
-
Your Spark job suddenly became four times slower after a recent deployment. How would you investigate the issue?
-
A Spark job is generating excessive Shuffle Read and Shuffle Write. What could be the possible reasons?
-
Your Spark application creates thousands of small output files. How would you solve this problem?
-
One Executor consistently takes much longer than others to complete its tasks. What would you investigate first?
-
Your Driver is running out of memory while processing a large dataset. What could be the possible reasons?
-
A join operation is taking significantly longer than expected. How would you optimize it?
-
Your Spark job processes billions of records every day. What optimization techniques would you implement?
-
Spark UI shows one Stage consuming most of the execution time. How would you identify the bottleneck?
-
Your Spark pipeline works correctly in development but becomes slow in production. What factors would you analyze?
-
A cached DataFrame does not improve performance. What could be the possible reasons?
-
You notice severe Data Skew in one of your production pipelines. How would you handle it?
-
AQE is enabled, but query performance is still poor. What additional optimizations would you consider?
-
Your Spark application is underutilizing cluster resources. How would you improve parallelism?
-
Cloud infrastructure costs for Spark workloads have increased significantly. How would you optimize both performance and cost?
-
Explain your step-by-step approach to tuning a Spark job that processes terabytes of data daily.
Spark Performance Rapid Fire Questions
Quickly revise these concepts before your interview.
- Narrow vs Wide Transformation
- Shuffle vs Broadcast Join
- Repartition vs Coalesce
- Cache vs Persist
- MEMORY_ONLY vs MEMORY_AND_DISK
- Driver Memory vs Executor Memory
- Storage Memory vs Execution Memory
- Parquet vs CSV
- Parquet vs ORC
- Predicate Pushdown vs Column Pruning
- Data Skew vs Uneven Partitioning
- Broadcast Join vs Sort Merge Join
- AQE vs Static Optimization
- Spark UI Jobs Tab vs Stages Tab
- Small Files vs Large Files
- Partition Pruning vs Partitioning
- collect() vs show()
- count() vs take()
- cache() vs checkpoint()
- File Compaction vs Repartition
Quick Revision Cheat Sheet
| Topic | Remember |
|---|---|
| Shuffle | Most expensive Spark operation |
| Partitioning | Controls parallelism |
| Repartition | Increases or decreases partitions with shuffle |
| Coalesce | Reduces partitions with minimal shuffle |
| Cache | Stores DataFrame in memory |
| Persist | Supports multiple storage levels |
| Broadcast Join | Best for small lookup tables |
| Data Skew | Uneven data distribution |
| Spark UI | Primary tool for debugging performance |
| AQE | Runtime query optimization |
| Parquet | Preferred columnar file format |
| Predicate Pushdown | Reads only required rows |
| Column Pruning | Reads only required columns |
| File Compaction | Reduces small file problem |
| Executor Memory | Memory used by Executors |
Interview Preparation Tips
Before attending a Spark Performance interview, ensure you can confidently explain:
- Why Shuffle is expensive and how to reduce it.
- When to use
repartition()versuscoalesce(). - The difference between
cache()andpersist(). - Broadcast Join and when it should be used.
- How to detect and resolve Data Skew.
- Spark UI components and the metrics you monitor.
- Memory tuning strategies for large Spark applications.
- How AQE improves query execution.
- Why Parquet is generally preferred over CSV.
- A complete performance tuning approach for a production Spark pipeline.
A good exercise is to take one of your existing Spark projects and identify at least five possible optimization opportunities. This practical thinking is often what interviewers look for in experienced Data Engineers.
Conclusion
Writing correct Spark code is only the first step. In production environments, the ability to optimize Spark jobs is equally important.
Understanding concepts such as Shuffle, Partitioning, Caching, Join Optimization, Spark UI, Memory Management, and Adaptive Query Execution enables you to build faster, more reliable, and cost-efficient data pipelines.
Use this guide as a revision checklist before your interviews, and make sure you can explain not only what each optimization technique is, but also when and why you would use it in a real-world project.
In the next article of this series, we will cover Spark Transformations & Actions Interview Questions, including narrow vs. wide transformations, commonly used transformations, actions, execution behavior, and production-oriented interview scenarios.