End-to-End Sales DataPipeline Project
Build a beginner-friendly Data Engineering project using Python, SQL, CSV files, data cleaning, validation, and database loading. This project is designed for freshers who want to understand how real data pipelines work.
What You Will Build
A raw-to-clean sales data pipeline.
Python scripts for ingestion and validation.
SQL queries for business reporting.
Interview-ready explanation of the project.
Code repository coming soon
The complete GitHub repo with datasets, Python scripts, SQL files, and README will be added shortly.
Project Architecture
How This Data Pipeline Works
This architecture shows how raw CSV files move through ingestion, validation, transformation, database loading, and SQL reporting.
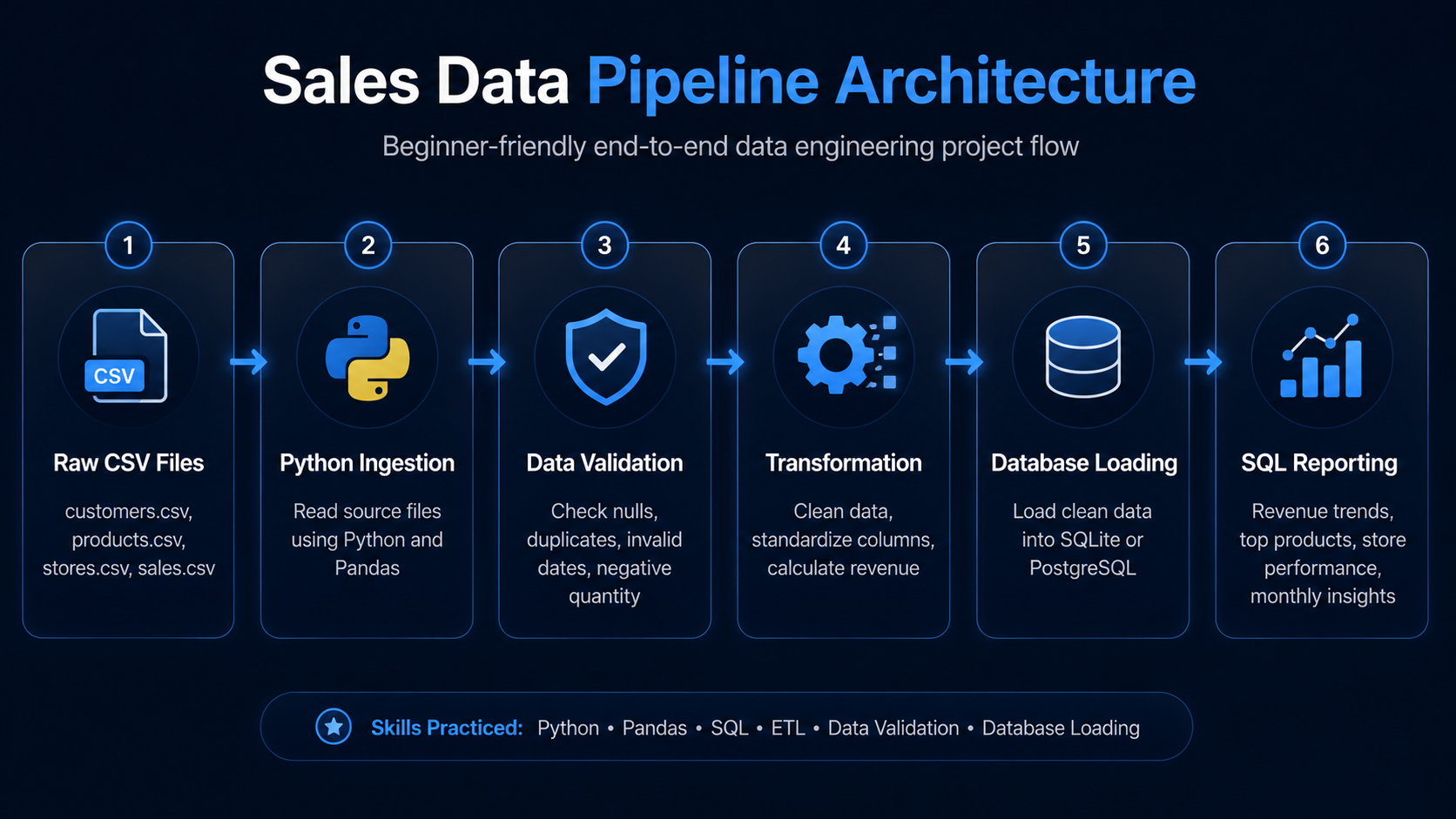
Raw Data Files
Work with CSV files like customers, products, stores, and sales.
Python ETL Logic
Use Python to read, clean, validate, and transform the data.
SQL Reporting
Load clean data into tables and write SQL queries for insights.
Project Flow
Step-by-Step Implementation
Understand the Business Problem
A retail company receives daily sales data from multiple stores and wants clean reporting-ready data.
Read Raw CSV Files
Load customers, products, stores, and sales files using Python.
Clean and Validate Data
Handle nulls, duplicates, invalid dates, negative quantities, and missing IDs.
Create Reporting Tables
Prepare clean tables that can be used for business analysis and dashboards.
Load Data into Database
Store cleaned data into SQLite or PostgreSQL tables.
Write SQL Analysis Queries
Analyze revenue, top products, store performance, and monthly trends.
Dataset
Files Used in This Project
These are the source files that will be included in the GitHub repository when the project code is published.
customer_id, customer_name, city, signup_date
product_id, product_name, category, price
store_id, store_name, city
order_id, order_date, customer_id, product_id, store_id, quantity, payment_mode
Complete GitHub Repository Will Be Added Soon
We are preparing the complete project repository with sample datasets, Python ETL scripts, SQL files, and a step-by-step README. Once ready, learners will be able to clone the repo and practice the project end to end.
Repository Will Include
✅ Sample CSV datasets
✅ Python ETL scripts
✅ SQL table creation scripts
✅ SQL analysis queries
✅ Step-by-step README guide
Interview Preparation
Questions You Should Prepare
✅ How did you design the pipeline from raw CSV to database tables?
✅ How did you handle duplicate records in the sales data?
✅ What validations did you apply before loading the data?
✅ How would you handle a missing daily sales file?
✅ How would you make this project incremental instead of full load?
✅ How would you move this project to cloud storage like S3 or ADLS?
✅ How would you schedule this pipeline daily?
✅ How would you monitor whether the pipeline ran successfully?
Start with this project before learning advanced tools.
Once you understand this project clearly, you can upgrade the same flow using PySpark, Airflow, cloud storage, and warehouse tools.