Spark Interview Questions Guide for Data Engineers
Apache Spark is one of the most important technologies in modern Data Engineering.
Whether you are preparing for:
- Data Engineering interviews
- Big Data roles
- PySpark developer positions
- Cloud Data Engineering jobs
Spark is almost always part of the interview process.
But one major mistake most candidates make is:
memorizing interview answers instead of understanding Spark concepts deeply.
In real enterprise interviews, companies focus heavily on:
- Spark architecture understanding
- optimization thinking
- debugging mindset
- partitioning concepts
- shuffle handling
- production problem solving
- real-world scenarios
This guide contains some of the most important Spark interview questions asked in real Data Engineering interviews.
The goal is not to memorize answers, but to understand how Spark works internally and how real-world Data Engineering systems are designed and optimized.
Spark Fundamentals Interview Questions
-
What is Apache Spark?
-
Why is Spark faster than Hadoop MapReduce?
-
What are the main components of Spark ecosystem?
-
Difference between RDD, DataFrame, and Dataset?
-
What is lazy evaluation in Spark?
-
What are transformations and actions?
-
What is DAG in Spark?
-
What happens internally when Spark job runs?
-
Difference between narrow and wide transformations?
-
What is shuffle in Spark?
-
Why are wide transformations expensive?
-
What is SparkSession?
-
Difference between SparkContext and SparkSession?
-
What is lineage in Spark?
-
What is fault tolerance in Spark?
Spark Architecture Interview Questions
-
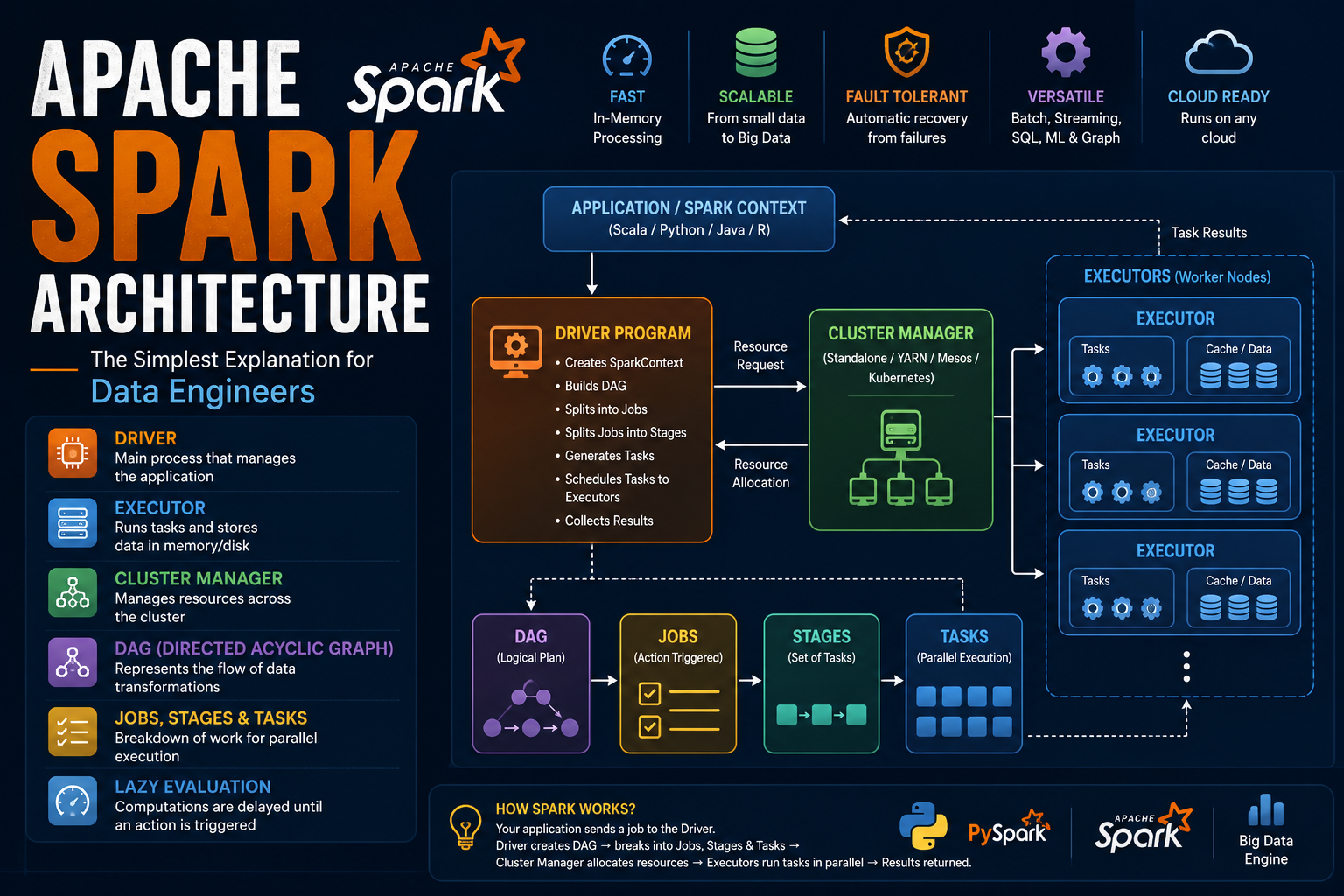
Explain Spark architecture.
-
What is the role of Driver in Spark?
-
What are Executors in Spark?
-
What is Cluster Manager in Spark?
-
What is task parallelism?
-
Difference between Job, Stage, and Task?
-
How does Spark distribute tasks across executors?
-
What happens when one executor fails?
-
What is speculative execution?
-
How does Spark achieve fault tolerance?
-
What is Catalyst Optimizer?
-
What is Tungsten Engine?
-
What is Adaptive Query Execution (AQE)?
PySpark DataFrame Interview Questions
-
Difference between repartition() and coalesce()?
-
Difference between cache() and persist()?
-
What is broadcast join?
-
What is predicate pushdown?
-
Difference between union() and unionByName()?
-
Difference between dropDuplicates() and distinct()?
-
What happens internally during groupBy() operation?
-
Why should collect() be avoided?
-
Difference between map() and flatMap()?
-
What is serialization in Spark?
-
What is partition pruning?
-
What are UDFs in Spark?
-
Why should excessive UDF usage be avoided?
Spark Optimization Interview Questions
-
How can you optimize Spark jobs?
-
What causes shuffle in Spark?
-
How can shuffle be reduced?
-
How do broadcast joins improve performance?
-
What causes data skew in Spark?
-
How do you handle skewed data?
-
Why should small files be avoided in Data Lakes?
-
What file formats are best for Spark workloads?
-
Difference between Parquet and CSV performance?
-
How does partitioning improve Spark performance?
-
How do you decide optimal partition count?
-
What is executor memory tuning?
-
What causes OutOfMemoryException in Spark?
-
Difference between caching and checkpointing?
-
Why should Spark UI be monitored regularly?
Scenario Based Spark Interview Questions
-
Your Spark job suddenly became very slow. How would you debug it?
-
One executor is taking much longer than others. What could be the reason?
-
Spark job failing with OutOfMemoryException. How would you troubleshoot?
-
Huge shuffle happening during joins. How would you optimize it?
-
Spark job generates thousands of small files. How would you solve this issue?
-
Pipeline runtime increased from 30 minutes to 4 hours. What would you investigate first?
-
How would you identify data skew in Spark?
-
Spark Streaming job starts lagging in production. How would you debug it?
-
A join operation is causing executor failures. What could be the possible reasons?
-
How would you optimize a Spark pipeline processing TB-level data daily?
-
How would you debug intermittent Spark job failures?
-
How would you reduce cloud cost for Spark workloads?
-
How would you optimize Spark jobs running on Databricks?
-
What would you monitor in production Spark pipelines?
-
What logs do you check first during Spark failure?
-
How do you debug failed Spark pipelines?
-
How do you handle SLA failures in Spark pipelines?
-
How do you optimize Spark cost in cloud platforms?
-
What metrics are important for Spark monitoring?
-
How do you identify bottlenecks in Spark jobs?
-
What would you do if Spark job runs successfully but produces incorrect output?
-
How do you handle retry mechanisms in Spark pipelines?
-
What is your approach for root cause analysis in Spark failures?
How to Prepare These Questions Effectively
Do not try to memorize Spark interview answers.
Instead focus on:
- understanding Spark internals
- learning optimization concepts
- practicing scenario-based debugging
- understanding Spark architecture deeply
- explaining concepts in your own words
- learning from real-world use cases
- understanding Spark UI and execution plans
Most modern Data Engineering interviews focus more on:
- practical thinking
- optimization mindset
- debugging approach
- architecture understanding
- production problem solving
rather than textbook definitions.
Want Structured Spark Interview Preparation?
If you want:
- guided Spark interview preparation
- scenario-based discussions
- real enterprise-level concepts
- mock interview guidance
- structured Data Engineering preparation
- practical optimization discussions
you can check out the Interview Preparation Series on Data with Soumya.