Complete Beginner-Friendly Guide to Apache Spark Architecture
If you are learning PySpark or Data Engineering, one topic that confuses almost every beginner is:
“How does Spark actually work internally?”
People hear terms like:
- Driver
- Executor
- Cluster Manager
- DAG
- Stages
- Tasks
- Lazy Evaluation
and suddenly Spark starts looking very complicated.
But honestly?
Spark Architecture becomes very easy once you understand it step-by-step visually and logically.
In this blog, we will learn Spark Architecture in the simplest beginner-friendly way possible.
By the end of this article, you will clearly understand:
- How Spark processes data
- What Driver does
- What Executors do
- How jobs are created
- What DAG means
- Difference between Jobs, Stages, and Tasks
- How parallel processing works
- Why Spark is so fast
- Real-world Data Engineering examples
This blog is designed specifically for beginners.
Why Spark Was Created
Before Spark, Hadoop MapReduce was widely used for big data processing.
But MapReduce had major problems:
- Very slow
- Heavy disk usage
- Complex coding
- Poor iterative processing performance
Spark solved these problems by introducing:
- In-memory processing
- Faster computation
- Better optimization
- Easier APIs
- Parallel distributed execution
Today Spark is one of the most important technologies in Data Engineering.
What is Apache Spark?
Apache Spark is a distributed data processing engine used for:
- Big Data Processing
- ETL Pipelines
- Streaming
- Machine Learning
- Data Analytics
Spark processes huge datasets across multiple machines in parallel.
That is the reason Spark becomes extremely fast.
Simple Real-World Analogy
Imagine you need to clean 10 million customer records.
If one person works alone:
- It takes very long
Instead:
- Divide work among 100 people
- Each person processes a portion
- Final result is combined
That is exactly how Spark works.
Spark distributes work across multiple machines.
High-Level Spark Architecture
At high level, Spark contains:
| Component | Purpose |
|---|---|
| Driver | Brain of Spark |
| Cluster Manager | Resource manager |
| Executors | Workers processing data |
| Worker Nodes | Machines running executors |
Spark Architecture Flow
User Application
↓
Driver Program
↓
Cluster Manager
↓
Executors
↓
Tasks Execute on DataThis is the complete high-level architecture.
Now let us understand each component deeply.
Driver Program (Brain of Spark)
The Driver is the most important component in Spark.
Think of Driver as:
“Project Manager of the Spark Application”
The Driver is responsible for:
- Reading Spark code
- Creating execution plan
- Dividing work
- Scheduling tasks
- Managing executors
- Tracking job execution
Without Driver, Spark cannot run.
What Happens Inside Driver?
When you write:
df.filter(col("salary") > 50000)Spark does NOT immediately execute it.
Instead:
- Driver reads your code
- Creates logical plan
- Optimizes execution
- Creates DAG
- Divides work into stages
- Sends tasks to executors
This is one of the most important Spark concepts.
Executors (Workers)
Executors are worker processes responsible for actual data processing.
Executors perform:
- Reading data
- Filtering rows
- Aggregations
- Transformations
- Writing output
If Driver is the brain:
Executors are the workers.Real Example
Suppose you have:
- 1 TB data
- 10 executors
Then Spark may divide workload into smaller chunks and distribute across all executors.
Each executor processes part of the data in parallel.
This parallelism is why Spark becomes fast.
Cluster Manager
Cluster Manager manages resources in the cluster.
Its job is:
- Allocate CPU
- Allocate memory
- Launch executors
- Manage nodes
Common Cluster Managers
| Cluster Manager | Usage |
|---|---|
| Standalone | Spark's own cluster manager |
| YARN | Hadoop ecosystem |
| Kubernetes | Modern cloud-native deployments |
| Mesos | Distributed cluster management |
Today Kubernetes is becoming very popular.
Worker Nodes
Worker Nodes are actual machines where executors run.
Example:
| Machine | Executor |
|---|---|
| Worker 1 | Executor 1 |
| Worker 2 | Executor 2 |
| Worker 3 | Executor 3 |
Each worker node contributes:
- CPU
- RAM
- Storage
Understanding Parallel Processing
Suppose we have:
100 million rowsSpark divides data into partitions.
Example:
| Partition | Executor |
|---|---|
| Partition 1 | Executor 1 |
| Partition 2 | Executor 2 |
| Partition 3 | Executor 3 |
Each executor processes data simultaneously.
This is called:
Parallel Distributed ProcessingWhat Are Partitions?
Partitions are smaller chunks of data.
Spark processes data partition-wise.
Example:
Large Dataset
↓
Partition 1
Partition 2
Partition 3
Partition 4More partitions usually improve parallelism.
But too many partitions also create overhead.
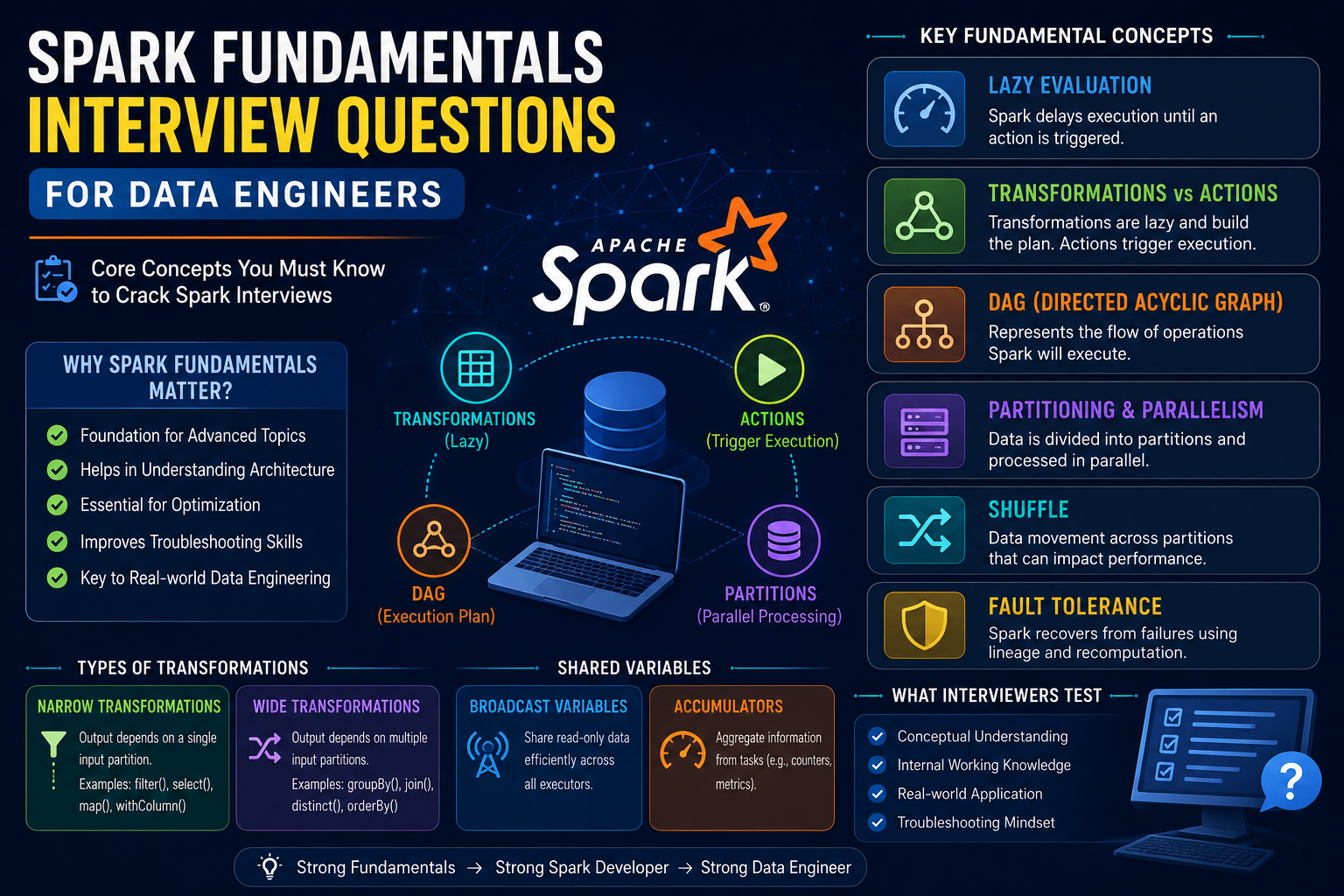
What is Lazy Evaluation?
This is one of the MOST important Spark concepts.
Spark transformations are lazy.
Meaning:
Spark does not execute immediately.
Example
df = spark.read.csv("employees.csv")
filtered_df = df.filter(col("salary") > 50000)
selected_df = filtered_df.select("name", "salary")Until now:
Spark has NOT executed anything.Spark only builds execution plan.
Actual execution starts only when an ACTION occurs.
What Triggers Execution?
Actions trigger execution.
Examples:
show()
count()
collect()
write()
save()Example
selected_df.show()Now Spark finally starts execution.
Why Lazy Evaluation is Powerful
Benefits:
- Better optimization
- Reduced unnecessary computation
- Improved performance
- Query optimization
Spark combines transformations intelligently.
Transformations vs Actions
Transformations
Create new DataFrame but do not execute.
Examples:
filter()
select()
groupBy()
join()
withColumn()Actions
Trigger execution.
Examples:
show()
count()
collect()
write()Understanding DAG (Directed Acyclic Graph)
DAG is another confusing topic for beginners.
But actually it is simple.
DAG represents:
Complete execution flow of Spark operationsExample
Suppose we do:
df.filter()
.groupBy()
.agg()Spark creates DAG internally.
Read Data
↓
Filter
↓
GroupBy
↓
AggregationThis execution flow is DAG.
Why DAG is Important
Spark uses DAG for:
- Optimization
- Efficient scheduling
- Parallel execution
- Fault tolerance
Understanding Jobs, Stages, and Tasks
This is VERY important for interviews.
Job
A Job is created whenever an Action is triggered.
Example:
df.show()creates one Job.
Stage
A Job is divided into multiple stages.
Stages are separated by shuffle boundaries.
Example operations causing shuffle:
- groupBy
- join
- distinct
- orderBy
Task
Each stage contains tasks.
One task usually processes one partition.
Simple Flow
Job
├── Stage 1
│ ├── Task 1
│ ├── Task 2
│ └── Task 3
│
└── Stage 2
├── Task 1
├── Task 2
└── Task 3What is Shuffle?
Shuffle means:
Moving data across executorsShuffle is expensive because it involves:
- Network transfer
- Disk I/O
- Serialization
Expensive Operations in Spark
These operations usually cause shuffle:
groupBy()
join()
distinct()
orderBy()
repartition()Why Spark Becomes Slow Sometimes
Common reasons:
- Too much shuffle
- Skewed data
- Large joins
- Too many partitions
- Too few partitions
- Excessive collect()
- Poor memory configuration
Spark Execution Example
Suppose we run:
df = spark.read.csv("sales.csv")
result = (
df.filter(col("amount") > 1000)
.groupBy("region")
.sum("amount")
)
result.show()Internal Execution Flow
Step 1
Driver reads code.
Step 2
Spark creates DAG.
Step 3
Logical plan gets optimized.
Step 4
Cluster Manager allocates executors.
Step 5
Tasks distributed across executors.
Step 6
Executors process partitions.
Step 7
Results returned to Driver.
Why Spark is Fast
Spark becomes fast because of:
- In-memory processing
- Parallel execution
- DAG optimization
- Lazy evaluation
- Distributed architecture
Real-World Data Engineering Use Cases
Spark is heavily used for:
- ETL pipelines
- CDC processing
- Batch processing
- Data lake transformations
- Machine learning pipelines
- Streaming analytics
- Large-scale joins
- Aggregation pipelines
Spark in Modern Data Engineering
Spark works with:
- Databricks
- AWS EMR
- Azure Synapse
- Microsoft Fabric
- Hadoop
- Delta Lake
- Iceberg
- Snowflake integrations
This makes Spark extremely important in modern data platforms.
Top 20 Spark Architecture Interview Questions
-
Explain Apache Spark architecture end to end.
-
What are the main components of Spark architecture?
-
What is the role of the Driver in Spark?
-
What is the role of Executors in Spark?
-
What is the role of Cluster Manager in Spark?
-
What is the difference between Driver and Executor?
-
What happens internally when we submit a Spark application?
-
What happens internally when an action like
show(),count(), orwrite()is triggered? -
What is Lazy Evaluation in Spark and why is it useful?
-
What is the difference between Transformation and Action in Spark?
-
What is DAG in Spark and why is it important?
-
What is the difference between Job, Stage, and Task in Spark?
-
How are stages created in Spark?
-
What is a Partition in Spark and how is it related to Tasks?
-
What is Shuffle in Spark and why is it expensive?
-
Which Spark operations usually cause Shuffle?
-
What is the difference between Narrow Transformation and Wide Transformation?
-
What happens if an Executor fails in Spark?
-
Why can using
collect()on huge data crash the Driver? -
Explain the complete Spark execution flow from reading data to writing final output.
Quick Revision Cheat Sheet
| Concept | Meaning |
|---|---|
| Driver | Brain of Spark |
| Executor | Worker processing data |
| Cluster Manager | Resource manager |
| Partition | Chunk of data |
| Transformation | Lazy operation |
| Action | Triggers execution |
| DAG | Execution flow graph |
| Job | Created by action |
| Stage | Group of tasks |
| Task | Smallest execution unit |
| Shuffle | Data movement across executors |
Conclusion
Spark Architecture is the foundation of PySpark and modern distributed data processing.
If you truly understand Spark internals, you can:
- Write better PySpark code
- Optimize jobs efficiently
- Troubleshoot failures
- Design scalable ETL systems
- Become a stronger Data Engineer
Spend time understanding Spark Architecture deeply because it is one of the most valuable long-term skills in Data Engineering.